Source: digitalinformationworld.com
At the beginning of this month, the Recorder app of Pixel 4 was made available for older Google phones as well. The company has now explained the machine learning behind the on-device transcription tool.
A post on Google AI blog describes the rationale for creating the Recorder app. Speech is the most effective way of communication but there not sufficient ways for capturing and organizing it. The company wants to make ideas and conversations easy to search and be accessible.
According to Google, in the last two decades, they have made the search easier to be in the form of text, visual content, maps, videos or even jobs. Still, most of the important information is recorded and shared in the form of speech, like conversations, lectures, interviews and more. Though it is often difficult to extract the required information from the hours of recording.
The Recorder app has three parts. An automatic speech recognition model, which was first introduced in Gborad in March this year, is powered by transcription that is built on the all-neural on-device system. A “Faster voice typing” is included in the Android keyboard that can work offline after downloading and transcribes character by character.
Hours-long sessions can be recorded on the Recorder and the word mapping to timestamps has been computed by the speech recognition model. Through this, users can click on the word of their choice from the transcript and listen from where they want to.
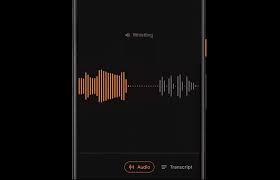
Though the text is a convenient form to present information but visual and sounds at times are more useful. Every bar of a waveform is of 50 milliseconds and is colored with the dominant sound in that period.
Audio is presented in a colored waveform in which each color identifies a different sound category. Convolutional Neural Networks (CNNs) are used to differentiate the sounds by comparing it with the already published datasets and classify each audio frame.
Also, Google allows three tags every time a recording ends that can be used to form a title for the video instead of using day and time. It helps the Recorder recognize the kind of content at the time of transcribing it.

