Source:
One of the coolest things serverless offerings do is allow you to “mix and match programming languages and frameworks like never before,” as Gartner research director Raj Bala has said. This means, as he suggested, you can write a Java application that calls Python libraries, for example, using a functions-as-a-service (serverless) platform.
It may also mean, however, a new era of spaghetti code (i.e., unstructured and difficult-to-maintain code). Just because you’re moving on from monolithic code (bad!) doesn’t mean that you’re not replacing it with “a distributed systems problem with implications for deployment, communication, monitoring, and so on” (also bad!), as Johannes Staffans has written. As with more traditional software development, developing easy-to-maintain microservices requires a thoughtful approach.
Spreading the microservices love
Bala is right to call out that one of the primary benefits of a serverless and “single-purpose microservices” is that “You can use the right tool for the right job rather than being constrained to one language, one framework or even one database.” This is immensely freeing for developers, because now instead of writing monolithic applications that likely have very low utilization with spiky workloads, they can build microservices tied to ephemeral serverless functions. When the system is idle, it shuts down and costs nothing to run. Everyone wins.
This also can make maintaining code more straightforward. For monolithic applications, updating code can present a major burden because of the difficulty inherent in covering all dependencies. As Ophir Gross has noted, “Spaghetti code is full of checks to see what interface version is being used and to make sure that the right code is executed. It’s often disorganized and usually results in higher maintenance efforts as changes in code affect functionality in areas that are challenging to predict during development stages.”
In a microservices-based approach, by contrast, “Code in a microservice is restricted to one function of the business and is thus easier to understand,” said Peter Eijgermans. Teams can operate independently of each other, using their own preferred implementation technologies and frameworks, among other things.
It’s not, however, with its own risks. Ironically, one of those risks just might be the spaghetti code that developers embrace microservices to escape.
Distributed spaghetti
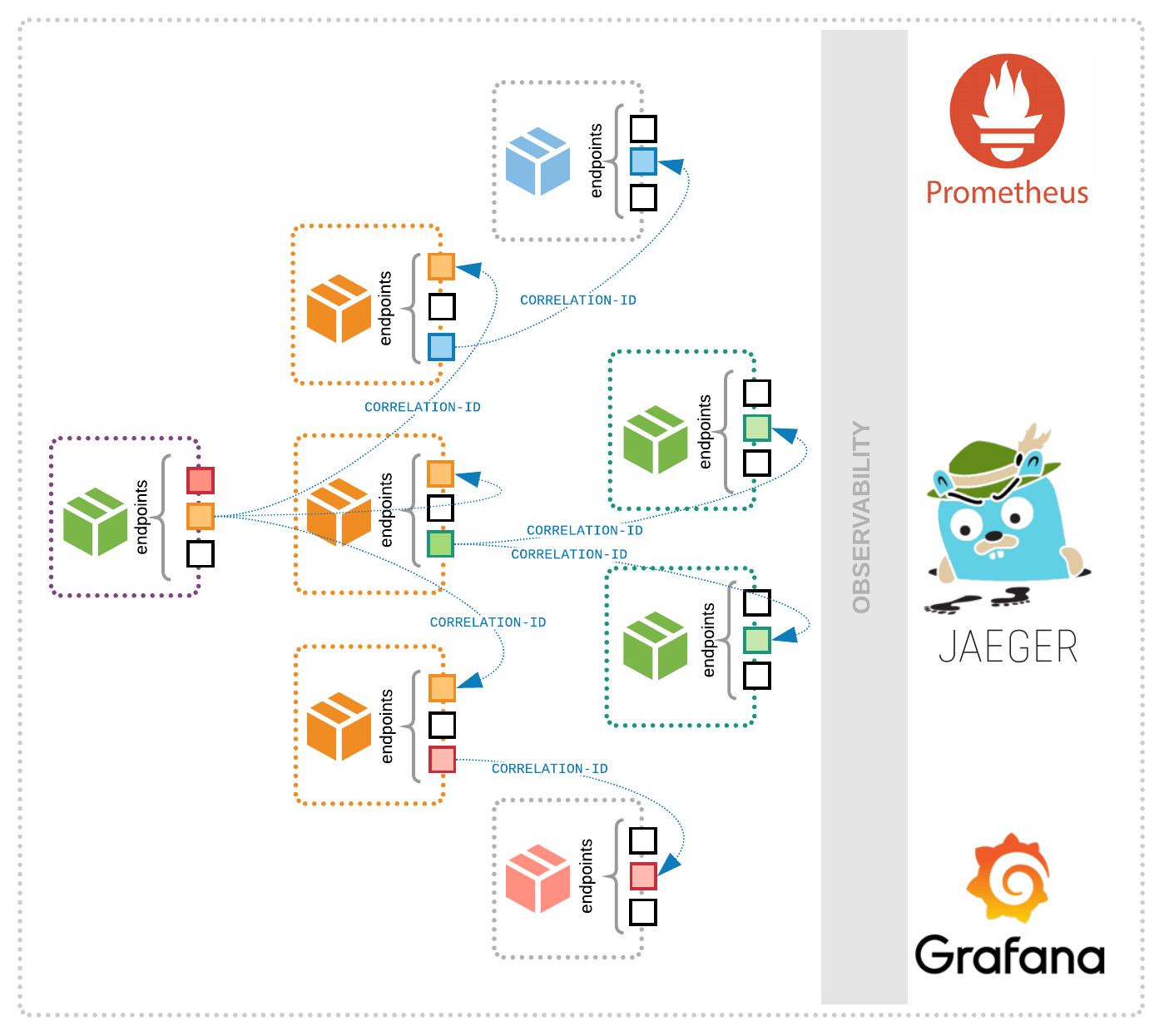
Among other complications (debugging is more complex, the difficulties associated with APIs changing over time and ensuring the services that consume the API are updated in a timely manner, etc.), one problem with microservices is that developers may use them to build in a similar manner to their monolithic application days. Eijgermans explained this problem:
People are often unaware that microservices really need to be independent. For example, you often see that all kinds of services are being made but that one database is shared. Another problem is that people program what they were used to doing in a monolith, making the chain of synchronous calls between services (over the network !!!) much too long. Neither is attention paid to spaghetti structure that can arise from all kinds of services that use each other and services are tightly coupled.
The key to designing microservices is to properly “defin[e] their boundaries and how they communicate,” according to Marko Anastasov. “A loosely coupled service contains related behavior in one place and knows as little as possible about the rest of the system with which it collaborates.” Anastasov’s emphasis on “loose coupling” is critical. You want services to communicate asynchronously with a limited number of endpoints and no shared database.
Of course this doesn’t eliminate the potential for “Spaghetti Code 2.0.” The very power and convenience that Bala calls out can lead to developers creating all sorts of API calls to serverless functions that can get unwieldy fast. Still, ensuring loose coupling of services can help.