Source – forbes.com
The first wave of cloud computing is attributed to platforms. Google App Engine, Engine Yard, Heroku, Azure delivered Platform as a Service (PaaS) to developers. The next big thing in the cloud was Infrastructure as a Service where customers could provision virtual machines and storage all by themselves. The third wave of cloud was centered around data. From relational databases to big data to graph databases, cloud providers offered data platform services covering a wide range of offerings. Whether it is AWS or Azure or GCP, compute, storage and databases are the cash cows of the public cloud.
The next wave that would drive the growth of public cloud is artificial intelligence. Cloud providers are gearing up to offer a comprehensive stack that delivers AI as a Service.
Here is a closer look at the AI stack in the public cloud.
 Source: Janakiram MSV
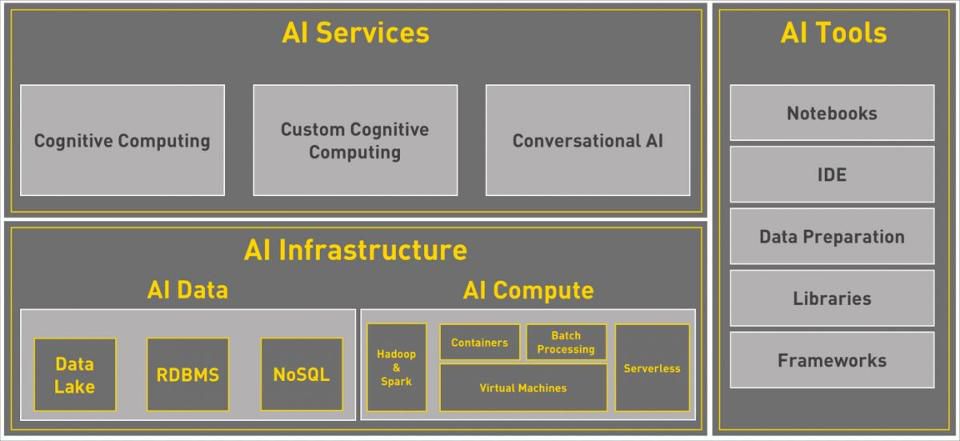
Source: Janakiram MSVAI Stack
AI Infrastructure
The two critical pillars of artificial intelligence and machine learning are data and compute.
Machine learning models are generated when a massive amount of data is applied to statistical algorithms. These models learn from a variety of patterns from existing data. The more the data, the better the accuracy of prediction. For example, tens of thousands of radiology reports are used to train deep learning networks, which will evolve models to detect tumors. Irrespective of the industry vertical and business problem, machine learning needs data which can be in multiple forms. Relational databases, unstructured data stored as binary objects, annotations stored in NoSQL databases, raw data ingested into data lakes act as input to machine learning models.
Deep learning and neural networks — advanced techniques of machine learning – perform complex computations that demand a combination of CPUs and GPUs. The Graphics Processing Unit complements the CPU through faster calculations. In the current context, GPUs are more expensive than CPUs. Cloud providers are offering clusters of GPU-backed VMs and containers through a pay-by-use model. With the data residing in the cloud, it makes perfect sense to exploit the compute infrastructure to train machine learning models.
Additional compute services such as batch processing, container orchestration and serverless computing are used for parallelizing and automating machine learning tasks. Apache Spark, the real-time data processing engine, is tightly integrated with machine learning.
Once the machine learning models are trained, they are deployed to VMs and containers for inference. The underlying elastic infrastructure powered by IaaS delivers web-scale computing to handle predictive analytics in production.
AI Services
Public cloud providers are exposing APIs and services that can be consumed without the need to create custom machine learning models. These services take advantage of the underlying infrastructure owned by the cloud vendors.
Cognitive computing APIs such as vision, speech, translation, text analytics and search are available as REST endpoints to developers. They can be easily integrated with applications with just one API call.
Even though cognitive computing delivers the power of AI through APIs, it can only handle generic use cases. To enable customers to enjoy the benefits of cognitive computing based on custom datasets, cloud vendors are moving towards custom cognitive computing. In this model, customers bring their own data to train cognitive services to deliver niche, specialized services. This approach removes the burden of choosing the right algorithms and training custom models.
Digital assistants are a big hit with end users. To enable developers to integrate voice and text bots, major cloud providers are exposing bot services. By consuming this service, web and mobile developers can easily add virtual assistants to their applications.
AI Tools
Apart from offering the APIs and infrastructure, cloud providers are competing to build tools for data scientists and developers. These tools are tightly integrated with the data platform and compute platform, which will indirectly drive the consumption of VMs, containers, storage, and databases.
Since setting up and installing the right data science environment is complex, cloud providers offer pre-configured VM templates that come with popular frameworks such as TensorFlow, Microsoft CNTK, Apache MXNet, Caffe and Torch. These VMs that are backed by GPUs act as the workhorses to train complex neural networks and machine learning models.
For entry-level data scientists, there are wizards and tools that abstract the complexity of training machine learning models. Behind the scenes, these tools take advantage of the scale-out infrastructure to create a multi-tenant development environment.
The efficiency of a machine learning model squarely depends on the data quality. To facilitate this, public cloud providers are offering data preparation tools that do the extract, transform, load (ETL) job. The output of these ETL jobs is fed to machine learning pipeline for training and evaluation.
Mature cloud providers are investing in integrated development environments and browser-based notebooks to ease experimentation and model management. Developers and data scientists feel at home when they use these familiar tools for building intelligent applications.
Public cloud providers are investing in AI to attract customers to their platforms. AI in the public cloud is still evolving. But it is turning out to be an essential driver for the adoption of compute and data services.