Source: psychologytoday.com
If alien anthropologists wanted to learn about human behavior, they would likely examine our literary works. Among the embarrassing flotsam, they would also discover Thomas Paine’s The Age of Reason, Toni Morrison’s Song of Solomon, or the lyrics to Bob Dylan’s “Blowin’ in the Wind.” The aliens might conclude that we are a troubled species, plagued by a mix of arrogance and ignorance, but with an overall trajectory that is progressive and promising.
The point is that there’s a treasure trove of information about our nature that can be extracted from the collective works of humanity. According to Google, there are approximately 130 million books in the world, and the company intends to scan all of them. So far, they’ve scanned about 30 million, and this impressive database is already being mined by scientists who are seeking answers to questions about our historical behavior.
Thirty million books contain an extraordinary amount of information, thus it qualifies as “big data.” As our computational ability to manage and probe large datasets increases, researchers are poised to answer queries that we couldn’t dream of addressing just a few years ago. Today, big data is routinely used in science laboratories—for example, when geneticists compare DNA sequences between tens of thousands of individuals to find correlations between gene variants and behavior (these are referred to as GWAS, or genome-wide association studies).
In much the same way geneticists can analyze millions of genes to learn about human physiology, scientists can scan millions of books to learn about human culture. And like “genomics,” this new science has been dubbed “culturomics” by its pioneers, Erez Aiden and Jean-Baptiste Michel. In their 2013 book, Uncharted: Big Data as a Lens on Human Culture, they mine the Google Book database to answer intriguing questions about our past behavior. It’s like asking questions of someone who has memorized the content of 30 million books spanning the existence of human civilization.
Remember learning about irregular verbs in grade school? For most verbs, we simply add an -ed suffix to denote the past tense: one dances today, but danced yesterday. This rule emerged a long time ago, between 500 and 250 BCE. So why do we say fell instead of falled in 2019? Drove instead of drived? Ate instead of eated? These pesky exceptions to the -ed rule are one of the things that make the English language so peculiar. Aiden and Michel used their big data approach to show that the adaptation of -ed correlated with the popularity of the word in question. In other words, today’s irregular verbs were used so commonly in the past that they resisted the -ed rule. Time does seem to catch up to these verbs, slowly but surely, and they estimate that of the 177 irregular verbs that remain, only 83 will still be irregular in the year 2500. Unfortunately, we will have drawed our last breath long before then, and won’t be around to verify this prediction.
In addition to our language quirks, culturomics can shine a spotlight on fame. By probing humanity’s books for someone’s name, one can get a sense of how famous that person was over time (although unique names like Mark Twain are less confounding than John Smith). Fame is a strange feature of human society—some people become popular because of their intelligence, heroism, or athletic prowess. Others because they have been naughty. And still others for dumb luck. Through clever probing of their dataset, Aiden and Michel not only identified the most famous people born each year between 1800 and 1949 but also which occupations were most likely to generate famous people. The top four included politicians, authors, actors, and scientists. As an author and a scientist, perhaps my odds are pretty good?
Culturomics can also be used to discern when a phrase became famous. Today’s ubiquitous holiday greeting, “Merry Christmas,” was practically absent from the literature until the year 1843. Why? That’s the year Charles Dickens published A Christmas Carol. Dickens should be acknowledged for popularizing “Merry Christmas” as much as “Bah…humbug!” Interesting facts about our inventions also emerge from analyzing big data. Some inventions, like the iPod, took off like wildfire. There’s another invention that is wildly popular today but took over a century to catch on: blue jeans.
As always, learning about our past vaccinates us against cultural ailments that caused great suffering among our forbearers. By surveying the dark periods of human history, culturomics teaches a haunting lesson. The data reveal a striking paucity of non-Nazi artists and authors in German literature during World War II, creating an unsettling gap on a graph of the country’s history. Lest we get too comfortable that such censorship never happens in the home of the free, a similar gap appears on a graph of blacklisted actors during the era of McCarthyism.
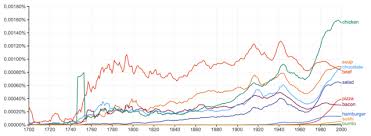
If you would like to probe the big data yourself, you can do so here. But be warned: this can be habit-forming! Here is a sample graph I generated that analyzes food trends over the centuries.
History can indeed be (re)written by the victors, making the preservation of big data all the more vital. The words humanity leaves behind are like the threads of a story quilt, and the lessons learned from big data may prevent it from becoming a burial shroud.