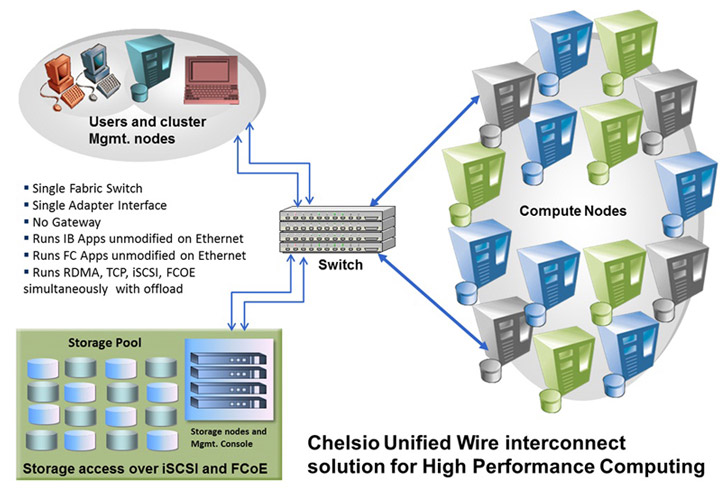
Introduction to High-Performance Computing Clusters
High-Performance Computing (HPC) clusters are crucial for organizations that need to process and analyze vast amounts of data in a short period. HPC clusters are a collection of interconnected computers that work together to perform complex calculations. These clusters are designed to handle large-scale computing tasks that are beyond the capabilities of a single machine.
What is High-Performance Computing?
High-Performance Computing (HPC) is the practice of using parallel processing and supercomputers to solve complex problems that traditional computing methods cannot handle. HPC clusters are designed to deliver a very high level of computational performance compared to traditional desktop computers or servers.
Why Organizations Need HPC Clusters?
Organizations in various fields such as research, finance, engineering, and healthcare, typically produce large and complex data sets that require HPC clusters to analyze, process and store them. HPC clusters are used to achieve faster results, solve complex computations, analyze large datasets and simulate complex systems.
Components of HPC Clusters
Hardware Components of HPC Clusters
The hardware components of HPC clusters typically include high-end processors, memory, high-speed network links, and storage devices. HPC clusters consist of several racks of servers, interconnected by high-speed networking fabrics, with advanced cooling and ventilation systems to prevent overheating.
Software Components of HPC Clusters
The software components of HPC clusters include operating systems, middleware, compilers, and libraries. The operating system is the core of the HPC cluster. Meanwhile, middleware provides a communication layer between nodes, allowing parallel processing. Compilers convert programming code into machine code, while libraries provide pre-written codes that can be used for different applications.
HPC Cluster Architecture and Design
HPC Cluster Topologies
HPC clusters can be designed with various topologies, such as the star, mesh, or tree topology. Each topology has its unique benefits and limitations. For example, a star topology is simple to implement, while a tree topology is more scalable.
HPC Cluster Network Structure
The network structure of an HPC cluster is a critical aspect of its design. The network interconnects the nodes in the cluster, allowing for data transfer between them. The network structure choice depends on the cluster’s size, the workload, and the topology.
Managing HPC Clusters: Software and Tools
Cluster Management Software
Cluster management software automates the process of configuring, provisioning, and administrating an HPC cluster. Management software tools, such as Bright Cluster Manager, WareWulf, and Ganglia, provide a simplified and centralized management interface.
Performance and Monitoring Tools for HPC Clusters
Performance and monitoring tools are critical for detecting issues or bottlenecks in an HPC system. Tools such as Nagios, Zabbix, and Icinga monitor system performance, network usage, and hardware failures, among others. These tools allow administrators to identify issues quickly and take action to prevent system failure.
Applications and Use Cases for HPC Clusters
High-Performance Computing (HPC) clusters are collections of interconnected computers that work together to solve complex problems that require a lot of computational power. Here are some of the common applications and use cases for HPC clusters.
HPC Clusters for Scientific Research
HPC clusters play a critical role in scientific research. Applications include modeling climate change, simulating protein folding, exploring astrophysics, and more. These tasks require massive amounts of computational resources that a single computer cannot provide. HPC clusters enable researchers to perform simulations and computations at a much faster rate.
HPC Clusters for Machine Learning and Artificial Intelligence
Machine learning and artificial intelligence (AI) applications also benefit from HPC clusters. These applications require processing massive amounts of data and running complex algorithms. HPC clusters enable data scientists to process data faster and train deep learning models more efficiently.
Considerations for Building an HPC Cluster
Building an HPC cluster is a complex process that requires careful planning and consideration. Here are some of the factors to consider when building an HPC cluster.
Cluster Size and Scalability
When building an HPC cluster, it’s important to consider the cluster size and scalability. The size of the cluster will depend on the workload and the number of users. Scalability is also an essential consideration because the cluster should be able to handle future growth and increasing workloads.
Cost Considerations for HPC Clusters
Cost is a significant factor when building an HPC cluster. The cost of the hardware, software, and infrastructure required can be substantial. It’s essential to consider the total cost of ownership, including maintenance and upgrade costs, when designing an HPC cluster.
Future of High-Performance Computing Clusters
The use of HPC clusters is expected to grow in the coming years. Here are some of the trends and advancements that we can expect in the future.
The Evolution of HPC Clusters
HPC clusters are continuing to evolve. One trend is the move towards hybrid systems that combine traditional CPUs with GPUs and other specialized hardware. Another trend is the use of containerization to make it easier to deploy and manage HPC clusters.
New Applications for HPC Clusters
As HPC clusters continue to evolve, we can expect to see new applications emerge. For example, HPC clusters could be used for simulating autonomous vehicles and improving healthcare outcomes through personalized medicine. As computing power continues to increase, the possibilities for HPC clusters are endless.As the amount of data that organizations generate continues to grow exponentially, the need for high-performance computing clusters will continue to increase. HPC clusters are a foundational asset in scientific research, machine learning, and artificial intelligence. This article aimed to provide insights into the components, architecture, management, and applications of HPC clusters, as well as future design considerations. With the continued evolution of HPC clusters, organizations will continue to push the boundaries of what is possible in data-intensive workloads, leading to new breakthroughs and discoveries.
FAQs about High-Performance Computing Clusters
What is the difference between High-Performance Computing and regular computing?
High-performance computing (HPC) is a form of computing that uses multiple processors and cores to perform complex computations. Regular computing, on the other hand, is typically performed using a single processor or core. HPC clusters are designed to handle large data sets and complex simulations that regular computing cannot handle.
What are the benefits of using an HPC cluster?
HPC clusters offer several benefits, including faster computation times, the ability to handle larger data sets, and the ability to perform complex simulations. HPC clusters are also highly scalable, which means that organizations can easily add additional nodes to the cluster as their computing needs grow.
How are HPC clusters managed?
HPC clusters are typically managed using cluster management software, which allows system administrators to manage the cluster and its resources. Cluster management software can be used to monitor the health of the cluster, manage the allocation of resources, and deploy software updates.
What are the design considerations when building an HPC cluster?
When building an HPC cluster, there are several design considerations that organizations should keep in mind. These include the size and scalability of the cluster, the network topology, the storage requirements, and the cooling requirements. Organizations should also consider the cost of building and maintaining a cluster, as well as the power and space requirements.


