Source – jaxenter.com
“Microservices Architecture” is now a popular concept in programming. In order to keep up-to-date as a software developer, I’ve been trying to get a good understanding of this architecture. Specifically, I’ve been looking at a better way to implement microservices architecture in Java using Spring.
Some background: my company, although great, had a woefully out of date tech stack. Basically, we weren’t using Java 8 or microservices yet. So I had to look outside of the company if I wanted to know more about either of those things. The easiest way to learn is by just doing it, so I decided to create a To Do system anddocument my experience for future reference.
Overview
My goal for this article is to have a source code walkthrough for different microservices. I’m not planning to go deep in the concepts and tools; there are a lot of posts about those out there. My intention here is to present an application example containing the patterns, tools, technologies used to develop microservices.
Since this is a reference application, I have intentionally made it as simple as possible so the source code is easy to understand. You should follow along at home and be able to run this application on your own computer as a reference.
In this article, we are going to work with a “To Do” application which will be composed of 8 applications:
- Reminder
- User
- Service discovery server
- Mailer
- OAuth Server
- System integration test
- API Gateway
- Web application client
This article will provide an overview of the whole project. Later, I will explain more deeply about what and how we are using the components in each microservice.
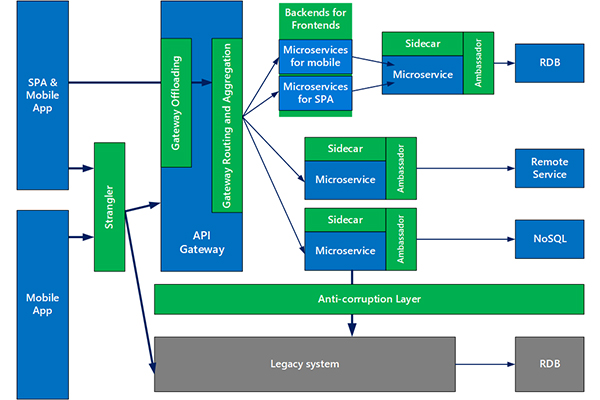
How our system will work with Microservices

In the image above, you can see how our system interacts along with all microservices. The user will access a Web Application written using Angular 2. It will then connect to an OAuth Authorization Server, which will be a central point of where users and authorities can be assigned. This server will return a JSON Web Token containing info about the client with its authorities and the grated scope. After the user is authenticated and has a token, the Web Application will be able to talk to the API gateway. It will take the JWT, verify if it’s coming from the Authorization Server, and then make calls to the microservices and build the response.
The OAuth server uses the User service to get the user’s authentication details. Also, the API gateway uses the OAuth server to get the user’s information.
The Remainder Service is where are placed the ToDo functionalities, The ToDo service has a scheduled job to check for reminders and notify the user by email, the emails are sent by the Mailer Service which is triggered from Reminder service by event using Kafka.
The System Integration Test is a Java application responsible for reaching the Reminder service’s endpoints.
Connecting Microservices
In Microservice architecture, we have to deal with many microservices running in different IPs and ports. Therefore, we need to find a way of managing each address without hard coding.
This is where Netflix Eureka comes to the rescue. It is a client-side service discovery that allows services to find and communicate with each other automatically. We are using Spring Cloud Eureka in our system; you should take a look at how it works so you can understand how our REST services are communicating between different microservices. Once Eureka cares about where the services are running, we can add instances and apply load balancing to distribute the incoming application traffic between our microservice.
In our system, we are using Netflix Ribbon as a client-side load balancer. That enables us to achieve fault tolerance and increase the reliability and availability through redundancy. We are using Netflix Foreign for writing declarative REST client, and integrating Ribbon and Eureka to provide a load balance HTTP client.
Our system does have some dependencies. We are trying to isolate our application from dependency failure using Netflix Hystrix Circuit Breaker. It helps stop cascading failures and allows us to fail fast and rapid recovery, or add fallbacks. Hystrix maintains a thread-pool for each dependency; it rejects requests instead of queuing them if the thread-pool becomes exhausted. It also provides circuit-breaker functionality that can stop all requests to a dependency. You can also implement fallback logic when a request is failed, rejected, or timed-out.
Authentication
Security is something very important when developing any kind of system. Microservices architecture is no different. “How can I maintain security in my microservices?” comes up immediately, and the first answer is OAuth2. OAuth2 is definitely a good solution: it is a well-known authorization technology that is widely used for Google, Facebook, and Github.
Anyways, it’s impossible to talk about security without mentioning Spring Security. I use it alongside OAuth2 in this project. Spring Security and OAuth2 are obvious choices when talking about secure distributed system.
However, we are adding one more element to our security concern: JSON Web Token (JWT). If we were only using OAuth, we would need to have an OAuth Authorization Server to authenticate the user, generate the token as well as act as an endpoint for the Resource servers to ask if the token is valid and which permission does it grant. This requires twice more requests to the Authorization Server than we really need. JWT provides a simple way of transmitting the permissions and user data in the access token. Once all data is already in the token string, the resource servers don’t need to ask for token checks. All the information is serialized into JSON first, encoded with base64 and finally signed with a private RSA key. It is assumed that all resource servers will have a public key to check if the token was signed for the proper private key and deserialize the token to have the information.
You can have a look at the OAuth2 Authorization Server(OAuth-server) and the Resource Server(API Gateway) implementations to see the code looks like. The implementation was done following mainly this blog post.
REST
In our system, we have two interaction styles: synchronous and asynchronous. For the async style, we are using distributed events with Kafka, following the model publish/subscribe. For synch, we have REST style supporting JSON and XML.
There are four levels of maturity of RESTful, starting at level 0, as described for Martin Fowler here. Our microservices is in the level 2, because I decided not implement the Hypermedia Controls using the HATEOAS design pattern for the simplicity.
Because we are using Spring Cloud, we have to out-of-box some scalability patterns, which are placed in our HTTP connections that deserve a mention: Circuit breaker, Bulkheads, Load Balancing, Connection pooling, timeouts, and retry.
Distributed Event
As mentioned above, our communication between the Reminder service and Mailer service is done asynchronously using Kafka to distribute our events across the others Microservices. In the Reminder service, we have a scheduled task to check for reminders time and publish the event RemainderFound. There will be a subscribed event in the Mailer service which will start the process of sending an email to the user. I invite you to have a look at how we are doing this integration and how I wrote the serialization/ deserialization of the data sent to Kafka in the Kafka event Module.
Event sourcing and CQRS
Monolithic applications typically have a single relational database. We can use ACID transactions. As a result, our application can simply begin a transaction, change multiple rows, and commit the transaction if everything go right or rollback if something goes wrong. Unfortunately, to deal with data access in the microservice architecture is much more complex. This is due to the fact that the data is distributed in different databases. Implementing business transactions across multiple services is a big challenge.
SEE MORE: From the Monolith to Microservices
In our “ToDo” project, we are using events to deal with business transaction that spans multiple services. You can look at the implementation of Event Sourcing with CQRS applied in the Mailer service. You can see how to separate Reads and Writes that enable us to scale each part easily. We are using a relational database as an event store and then distributing the events using Kafka. We will need to make these two actions Atomic and avoid storing the event, that way it won’t publish an eventual JVM crash. I’m not using Kafka as the event store because is simpler to construct the aggregates from a relational database. We are trying to make things easy here!
Next step
As you can notice, we already have a lot of things in this project and there are still many challenges that are not addressed here yet. However, this is a project in development and we are planning adding more things into it, such as Spring cloud config, Containers with Docker, continuous integration with Jenkins, Distributed trace with Spring Sleuth, Logging management with ELK and more. So keep tuned on our Github repository to see more fun things.