Source: jaxenter.com
Microservices were supposed to make everything faster, but the reality for many Java developers is a new layer of complexity that can lead to performance problems. In parallel, developers are increasingly tasked with troubleshooting performance issues. For instance, a recent survey by JRebel found that 51% of Java developers are tasked with non-functional performance requirements during development.
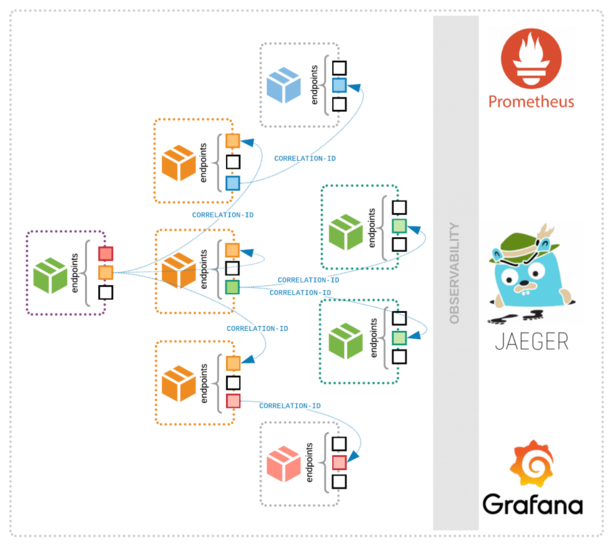
The first step is to find those performance issues. Application performance monitoring tools identify issues during development and production, while service mesh solutions streamline inter-service communications and provide insight. Testing tools look at how microservices will function — or fail — at load, while profiling tools plug into the test environment to assess performance issues, such as memory leaks and threading issues.
Early stage analysis and optimisation are also important. Seeing how code is interacting with other services fits in well with DevOps, helping developers see the impact their work will have in production.
Eight Common Microservices Performance Problems
That early stage analysis also helps developers identify likely performance culprits. But, as we show in the following examples, not all microservices performance issues are equal: some are easy to fix, while others require more effort.
1. N+1 Problems
Also known as an N+1 Select Problem or N+1 Query, this occurs when a service requests a list from a database that returns a reference to a number of rows or objects (N), then individually requests each of those N items.
Fortunately, the solution can be as simple as changing a fetch type.
2. Performance Antipatterns
The N+1 problem is one example of antipatterns. Performance antipatterns typically centre around inefficient or superfluous queries that compound at load or scale. These performance antipatterns can occur for a variety of reasons, and only appear in specific instances, but can result in poor performance or even cascading failure.
Examples include adding timeout and retry functions. While theoretically a good idea, if the service being called is very slow and always triggers a timeout, the retry puts extra stress on an already overloaded system, exacerbating latency issues.
3. Synchronous Requests
Calling a service synchronously in the wrong situation can cause significant performance bottlenecks, both for individual services and for the combined application.
To solve this, use asynchronous requests, whereby a service can make a request to another service and return immediately while that request is fulfilled, thus allowing for more concurrent work. However, developers need to ensure that the receiving service can fulfill requests quickly, and scale to handle a high volume of requests as needed.
4. Overactive Services
Is a microservice receiving too many requests to handle? Throttling requests or using fixed connection limits on a service by service basis can help receiving services keep up with demand. Throttling also prevents overactive services from starving out less active, but equally important services.
There is a trade-off — throttling will slow down the application — but it is better than the application failing altogether.
5. Third-Party Requests
Sometimes, a third-party service or API can cause significant issues for an application, such as unacceptable latency. This is why it’s essential for developers to understand the limitations of a third-party, particularly at-scale.
Questions to ask include: can they keep up with anticipated demand and maintain performance? Is the SLA compatible with the application’s own?
Proactive best-practice steps also help, such as caching, pre-fetching, or using resiliency patterns to prevent services from causing cascading failures.
6. Application Ceilings
Even properly configured and optimised services can have performance ceilings. If all requests are deemed necessary and optimised, yet overloading of the service is still happening, then load balancing across additional containers should improve scalability. It is also worth looking at autoscaling, to dynamically adjust to incoming request load by adding and removing containers as necessary.
However, make sure to implement a maximum container count and have a strategy for defending against Distributed Denial of Service (DDoS) attacks, especially if the application is in a public cloud.
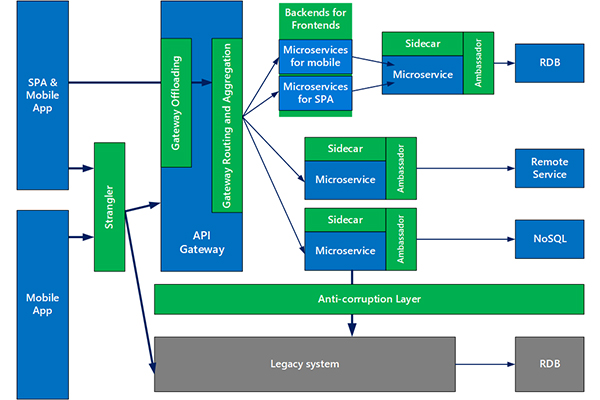
In addition, clustering technology, and potentially moving some services to NoSQL solutions to achieve higher scale than possible with an RDBMS. However, be prepared to deal with eventual consistency and compensating operations if ACID-like transactions are needed across services.
7. Data Stores
Microservices give developers the flexibility to use multiple data stores within an application, but choosing the wrong database type can have major performance (and monetary) consequences.
Select data stores for microservices on a service-by-service level, making sure that each one is suited to the job.
For handling lots of fast-changing unstructured data, it may be better to use a scalable or schema-less NoQSL data store.
For cases where data atomicity, consistency, isolation, and durability are needed, a RDBMS should be used.
8. Database Calls
When a service requests data from multiple databases, each of those databases has the capacity to hold up that request. If this happens frequently, caching that information in a single, easily accessible place — rather than relying on multiple databases — can relieve the problem. Universal rules can be set, such as time limits and prevention of excessive calls.
Memory caching is used in high performance and distributed systems to store arbitrary data for rapid local access. Some database systems offer native in-memory caching.
Final Thoughts
Clearly, addressing performance issues in Java-based microservices is not a simple, one-off task. Given the growth and increasing dependence on them, however, it is too big an issue to ignore.
Now is the time to put in place a robust strategy to solve problems today and mitigate them in the future.