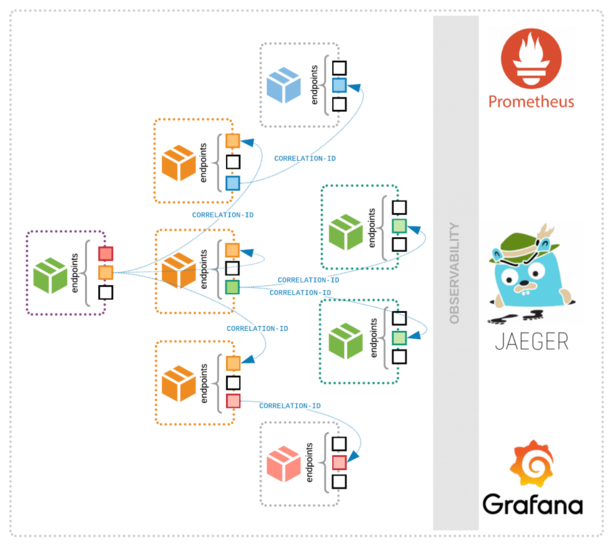
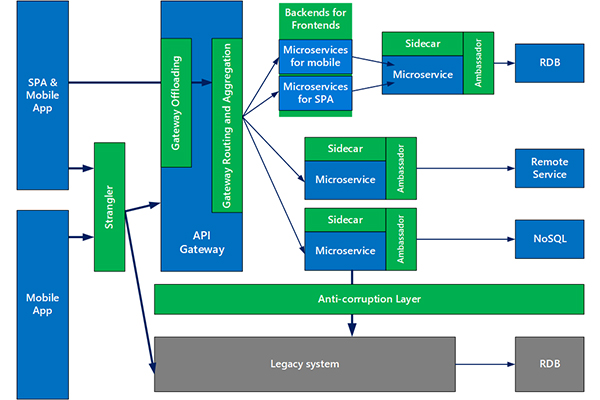
Source: information-age.com
Microservices are a way to build applications based on small components that are used for specific requirements. IDC has predicted that 90 percent of applications will use microservices architectures by 2020. Many of the world’s largest brands, including Google, Netflix, and Uber have either moved or are migrating to a microservices architecture approach.
Rather than large, monolithic applications or traditional three-tier apps, microservices-based applications should be easier to update and add new functionality to. For chief information officers (CIOs), adopting microservices should lead to happier developers and faster application deployments.
However, for chief data officers (CDOs), the move to microservices can be a blessing and a curse. The reason for this is that adopting microservices can lead to a deluge of new data that can be harder to deal with at scale. Without the right approach to data management and modelling alongside application design, there can be problems for enterprises.
So, how can CIOs and CDOs collaborate to make the most of this microservices approach to applications, and how can this be applied equally to data?
Stateless applications and data
Typically, microservices applications are deployed using software containers or serverless computing functions. The application components exist for as long as they are running, and then are shut down; these components are therefore stateless. However, the data that these components create has to stored over time in a stateful manner. There are two elements to this – the first is the data created by the application component as part of its operation, and the second are the specific results that the application is designed to create.
As an example, let’s look at a retail application based on microservices. One application component would run the shopping basket and integrate with the user, another would process any payment, a third would manage delivery, and a final one would update the user’s account with updated information on their order. Each application component would create data for permanent retention in a database, while each would also create metadata on how well it performed.
This data all has to be stored – a database would be the usual option for a task like this, but a traditional database is not designed to work with stateless application components that can scale up or down based on demand levels. While microservices are stateless by design, they still need to be able to interact with a database to store or retrieve transactional data. However, in order to follow a microservices architecture pattern, each microservice’s persistent data must be private and no other microservice can access that data directly.
There are several ways to achieve this: create a set of tables for each service, create a dedicated private schema, or create a dedicated database for each service. While private tables or schema have the lowest overhead, some high throughput services might benefit by having their own private database. In general, using a private schema or database per service is most appealing since it clearly defines ownership and provides encapsulation.
Running your database in the same way as your application
The big issue for implementing and supporting a database strategy underneath a microservices application is how to manage this over time. Individual database instances can be used to support each element – in our retail application example, a database instance could store all the necessary details on customer details and deliveries while a third party payments application might handle all the payments records securely. However, this only tends to work as an approach based on applications based on predictable traffic patterns.
For other application components that may scale up and down based on traffic levels, this may be less appropriate. Adding more containers to cope with demand is a natural step for these kinds of applications, and is often automated using something like Kubernetes. For databases that have to cope with this scale-up activity, integration is essential. If more containers are created and start providing data back, then the database service will have to cope with that increase in the number of connected components and the increase in the volume of data.
Typically, traditional databases can only scale vertically for both read and write operations, meaning that CPU, memory, and storage have to be added to an existing host machine to accommodate growth. Horizontal scaling can be achieved through sharding and a master-slave architecture; however, this introduces additional complexity and increases the potential chance for failure. Keeping replicas in sync, dealing with anticipated downtime when switching out a master node, and having replicas that are read-only makes management harder.
In this case, a distributed database like Apache Cassandra can be a better fit as the database component. This can support the distributed nature of microservices applications more easily, while also still centralising the database instance to make it easier to store data over time around transactions. For example, UK bank Monzo has a fully microservices-based set of services to run its operations serving more than three million customers, including more than 1,500 services. This is all linked into one database instance running on Cassandra.
Alongside the distributed data element, it is worth looking at how any database will integrate with services like Kubernetes through Operators that can manage the automated tasks of scaling up new clusters.
Implementing microservices and data together at scale
For CIOs and CDOs, scaling up microservices applications to cope with customer demand is a prerequisite for success. Alongside this, any approach to data has to scale up as well. Microservices applications can reside across multiple data centre environments around the world, or be implemented across hybrid cloud deployments to provide that scale and still provide instant access to data like customer orders or shopping cart details. This can address application requirements like high availability with no latency, while still maintaining compliance with local regulations such as keeping data within a certain geography.
Keeping your data strategy in line with your application strategy can help in this case. Where applications have moved to microservices, looking at how to apply the same model to data should be a natural next step. As application components have become more distributed, so the data that they create will potentially get more distributed too. Looking at a distributed database approach should help CIOs and CDOs keep up, ensuring that the data side of applications does not fall behind or lead to problems over time.