Source – insidebigdata.com
Technologies such as smart sensors and the Internet of Things (IoT) are enabling vast amounts of detailed data to be collected from scientific instruments, manufacturing systems, connected cars, aircraft and other sources. With the proper tools and techniques, this data can be used to make rapid scientific discoveries and develop and incorporate more intelligence into products, services, and manufacturing processes.
While scientists and engineers have the domain knowledge and experience to make design and business decisions with this data, additional software analysis and modeling tools may be needed to take product differentiation to the next level. Using platforms that supports these big data needs offers scalability and efficiency, while providing companies with a competitive advantage in the global marketplace.
For some potential big data users, gaining access to and actually integrating analytics tools into a workflow may seem like an intriguing, yet daunting task. Fortunately, today’s software analysis and modeling tools have been enhanced with new capabilities to make working with big data easier and more intuitive. With these tools, engineers and scientists can become data scientists by accessing and combining multiple data sets and creating predictive modelsusing familiar syntax and functions.
To efficiently capture and incorporate the benefits of big data, engineers and scientists need a scalable tool that provides access to a wide variety of systems and formats used to store and manage data. This is especially important in cases where more than one type of system or format may be in use. Sensor or image data stored in files on a shared drive, for example, may need to be combined with metadata stored in a database.
In certain instances, data of many different formats must be aggregated to understand the behavior of the system and develop a predictive model. For example, engineers at Baker Hughes, a provider of services to oil and gas operators, needed to develop a predictive maintenance system to reduce pump equipment costs and downtime on their oil and gas extraction trucks. If a truck at an active site has a pump failure, Baker Hughes must immediately replace the truck to ensure continuous operation. Sending spare trucks to each site costs the company tens of millions of dollars in revenue that could be saved if the vehicles were active at another site. The inability to accurately predict when valves and pumps will require maintenance underpins other costs. Too-frequent maintenance is wasteful and results in parts being replaced when they are still usable, while too-infrequent maintenance risks damaging pumps beyond repair. To strike a balance, engineers at Baker Hughes used MATLAB to collect terabytes of data from the oil and gas extraction trucks and then developed an application that predicts when equipment needs maintenance or replacement.
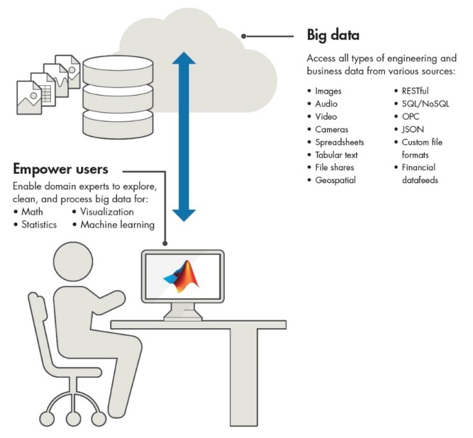
Figure 1: Access a wide range of big data. Copyright: © 1984–2017 The MathWorks, Inc.
Analyzing, Processing, and Creating Models
As in the case of Baker Hughes, engineers and scientists looking to efficiently capture the benefits of big data need a scalable tool to sort through different formats and understand the behavior of the system before developing their predictive models.
Software analysis and modeling tools can simplify this exploration process, making it easier for engineers and scientists to observe, clean, and effectively work with big data and determine which machine learning algorithms should be used across large datasets to implement a practical model. After accessing the data and before creating a model or theory, it’s important to understand what is in the data, as it may have a major impact on the final result.
Often, when creating a model or theory, the software can help decipher the data and identify:
- slow moving trends or infrequency events spread across the data
- bad or missing data that needs to be cleaned before a valid model or theory can be established
- data that is most relevant for a theory or model
Additionally, big data tools can assist with feature engineering in which additional information is derived for use in later analysis and model creation.
Exploring and Processing of Large Sets of Data
Let’s look at some of the capabilities that can help to easily explore and understand data, even if it is too big to fit into the memory of a typical desktop workstation.
- Summary visualizations, such as binScatterPlot (Figure 2) provide a way to easily view patterns and quickly gain insights.
- Data cleansing removes outliers, and replaces bad or missing data to ensure a better model or analysis. A programmatic way to cleanse data enables new data to be automatically cleaned as it’s collected. (Figure 3).
- Data reduction techniques, such as Principal Component Analysis (PCA), help to find the most influential data inputs. By reducing the number of inputs, a more compact model can be created, which requires less processing when the model is embedded into a product or service.
- Data processing at scale enables engineers and scientists to not only work with large sets of data on a desktop workstation, but use their analysis pipeline or algorithms on an enterprise class system such as Hadoop. The ability to move between systems without changing code greatly increases efficiency.
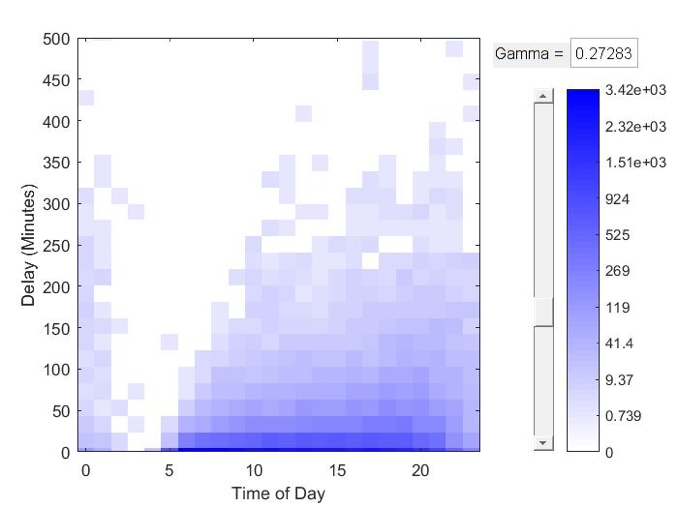
Figure 2: binScatterPlot in MATLAB. Copyright: © 1984–2017 The MathWorks, Inc.

Figure 3: Example of filtering big data with MATLAB. Copyright: © 1984–2017 The MathWorks, Inc.
Incorporating Big Data Software for Real-World Solutions
To truly take advantage of the value of big data, the full process – from accessing data to developing analytical models to deploying these models into production – must be supported. However, incorporating models into products or services is typically done in conjunction with enterprise application developers and system architects and can create a challenge because developing models in traditional programming languages is difficult for engineers and scientists.
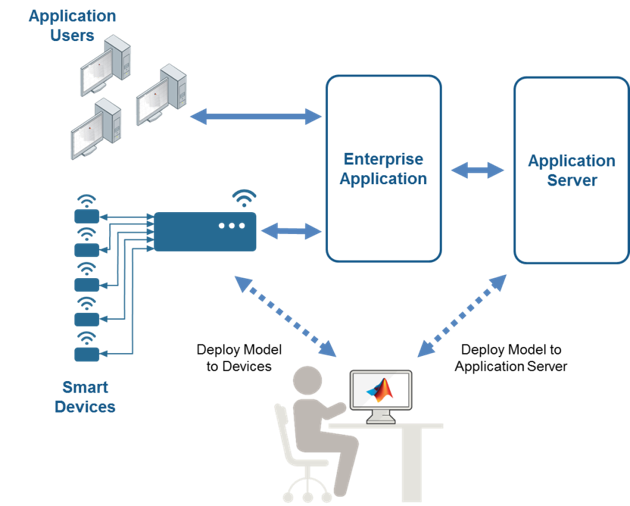
Figure 5: Integrating models with MATLAB. Copyright: © 1984–2017 The MathWorks, Inc.
To alleviate this issue, enterprise application developers should look for data analysis and modeling tools that are familiar to their engineers and scientists. By leveraging certain software analysis and modeling tools, scientists and engineers can explore, process, and create models with big data using familiar functions and syntax, while providing the ability to integrate their models and insights directly into products, systems, and operations. Simultaneously, the organization is being enabled to rapidly incorporate these models into its products and services by leveraging production-ready application servers and code generation capabilities that are found in these tools.
Access to tools that provide scalability and efficiency enable domain experts to be better data scientists and give their companies a competitive advantage in the global marketplace. The combination of a knowledgeable domain expert who has been enabled to be an effective data scientist, along with an IT team capable of rapidly incorporating their work into the services, products and operations of their organization makes for a significant competitive advantage when offering the products and services that customers are demanding.