Source – networkworld.com
Nvidia and server makers Dell EMC, HPE, IBM and Supermicro announced enterprise servers featuring Nvidia’s Tesla V100 GPU. The question is, can servers designed for machine learning stem the erosion of enterprise server purchases as companies shift to PaaS, IaaS, and cloud services? The recent introduction of hardened industrial servers for IoT may indicate that server makers are looking for growth in vertical markets.
There are very compelling reasons for moving enterprise workloads to Amazon, Google, IBM and other hosted infrastructures. The scalability of on-demand resources, operating efficiency at cloud-scale and security are just three of many reasons. For instance, Google has 90 engineers working on just security where most enterprises are understaffed.
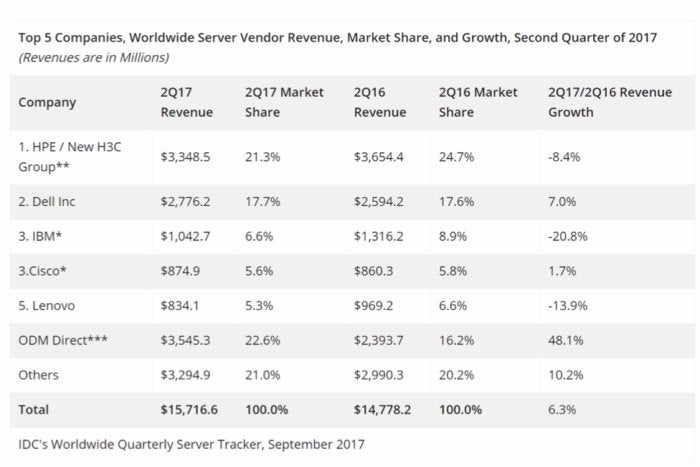
Last quarter, every enterprise server company posted declining revenues except for Dell. The server business is growing but not in the enterprise segment. The cloud companies do not purchase much from them. Instead, they purchase components built to their specification and build their infrastructure optimized for their enormous 24X7 workloads. Competitors — Google, Facebook, IBM and other cloud companies — collaborate on engineering and specifying new hardware components through the Open Compute Project founded by Facebook. The cloud companies are buying directly from the server makers supply chain. Declines during previous quarters demonstrate that this is a difficult-to-reverse, long-term trend.
The enterprise machine learning market is still young, but these servers will deliver high margins. Delivering powerful servers with GPUs optimized for the machine learning workloads of enterprise innovators will be profitable. Being early is important to acquiring market share as the sector matures.
Nvidia takes a page from Intel’s playbook
Nvidia is the Intel of the machine learning and AI. And with its Volta architecture, it is following a page from Intel’s playbook. Intel won its dominance in PC and server platforms by working on open standards for interfacing with other comment makers, such as memory and hard drives, and publishing reference specifications to guide systems makers such as Dell, Lenovo, and many smaller manufacturers to design systems optimized for price and performance for PC and server use cases.
Looking at the Volta Architecture white paper, this is exactly Nvidia’s approach but a different use case: neural networks. Neural networks apply computational resources to solve machine learning linear algebra problems with very large matrices, iterating to make statistically accurate decisions. Neural networks are computationally intensive because they need to update millions of parameters numerous times to minimize error and produce an accurate model. Those updates are basically large matrix multiply operations.
Though there are many different types of machine learning and AI, most applied machine learning is supervised. Supervised means training the machine learning models with labeled datasets, for example, a large corpus of sentences and their translation into another language are fed into the neural network to train it, or to create a model that translates from one language into another. After the model reaches a desired level of accuracy, the model can be deployed as an inference model that infers based on statistical probability of accuracy. The only way to train neural networks on very large datasets is to either give them a lot of time or a lot of GPUs operating in parallel and a lot of shared memory.
Machine learning is an empirical science. It takes many iterations for engineers to learn how to train neural networks to understand a new use case. Even the most experienced machine learning expert cannot say for sure whether a five-value or 5,000-value vector is needed to train a model. That means a lot of experiments to create a model for a new use case and then optimize to fit a computational budget with an ROI.
Snap Chat’s Hussein Mehanna once told me when he led the core machine learning team at Facebook that “long training times will kill an engineer,” meaning having to wait for training run to complete, sometimes lasting weeks. will interrupt progress solving a critical problem and frustrate the engineer trying to solve the problem.
Most of the machine learning models in operation today started in academia, such as natural language or image recognition, and were further researched by large well-staffed research and engineering teams at Google, Facebook, IBM and Microsoft. But these problems are siloed to match these companies’ use cases, search ranking, image and object recognition, etc. They are often open source and available to an enterprise, but they may not apply to an enterprise’s use case. Enterprise machine learning experts and data scientists will have to start from scratch with research and iterate to build new high-accuracy models.
Nvidia’s Volta Architecture
The Volta Architecture includes many of the features used in supercomputers to speed computation and optimize formerly CPUs and now GPUs, memory and interconnect bandwidth.
- The Volta Architecture uses a streaming multiprocessor optimized for Deep Learning, tuned for mixed computation and addressing calculations. Parallel processing is improved by fine-grained synchronization and cooperation between parallel threads. Connected L1 data cache and shared memory significantly improve performance and simplify programming.
- It has a high-speed interconnect with higher bandwidth. More connections between multi-GPU systems increases scalability and parallelism.
- The memory subsystem delivers 900 GB/sec peak memory bandwidth using Samsung HBM2 memory fast memory that can use up to 95 percent memory bandwidth utilization running many workloads.
- A multi-process service improves performance, isolation and quality of service for multiple compute applications sharing the GPU.
- In multi-GPU applications, getting the data close to the GPU executing instruction speeds performance. Unified memory and address translation services migrate memory pages to the processor that accesses them most frequently, improving efficiency for memory ranges shared between processors.
Nvidia has given its enterprise server partners an architecture designed for them to sell to enterprises investing in machine learning. It is a specialty business because the enterprises need four characteristics not necessarily found together: a large corpus of data for training, highly skilled data scientists and machine learning experts, a strategic problem that machine learning can solve, and a reason not to use Google’s or Amazon’s pay-as-you-go offerings.