Source – blog.risingstack.com
A Microservices architecture makes it possible to isolate failuresthrough well-defined service boundaries. But like in every distributed system, there is a higher chance for network, hardware or application level issues. As a consequence of service dependencies, any component can be temporarily unavailable for their consumers. To minimize the impact of partial outages we need to build fault tolerant services that can gracefully respond to certain types of outages.
This article introduces the most common techniques and architecture patterns to build and operate a highly available microservices system based on RisingStack’s Node.js Consulting & Development experience.
If you are not familiar with the patterns in this article, it doesn’t necessarily mean that you do something wrong. Building a reliable system always comes with an extra cost.
The Risk of the Microservices Architecture
The microservices architecture moves application logic to services and uses a network layer to communicate between them. Communicating over a network instead of in-memory calls brings extra latency and complexity to the system which requires cooperation between multiple physical and logical components. The increased complexity of the distributed system leads to a higher chance of particular network failures.
One of the biggest advantage of a microservices architecture over a monolithic one is that teams can independently design, develop and deploy their services. They have full ownership over their service’s lifecycle. It also means that teams have no control over their service dependencies as it’s more likely managed by a different team. With a microservices architecture, we need to keep in mind that provider services can be temporarily unavailable by broken releases, configurations, and other changes as they are controlled by someone else and components move independently from each other.
Graceful Service Degradation
One of the best advantages of a microservices architecture is that you can isolate failures and achieve graceful service degradation as components fail separately. For example, during an outage customers in a photo sharing application maybe cannot upload a new picture, but they can still browse, edit and share their existing photos.

Microservices fail separately (in theory)
In most of the cases, it’s hard to implement this kind of graceful service degradation as applications in a distributed system depend on each other, and you need to apply several failover logics (some of them will be covered by this article later) to prepare for temporary glitches and outages.

Services depend on each other and fail together without failover logics.
Change management
Google’s site reliability team has found that roughly 70% of the outages are caused by changes in a live system. When you change something in your service – you deploy a new version of your code or change some configuration – there is always a chance for failure or the introduction of a new bug.
In a microservices architecture, services depend on each other. This is why you should minimize failures and limit their negative effect. To deal with issues from changes, you can implement change management strategies and automatic rollouts.
For example, when you deploy new code, or you change some configuration, you should apply these changes to a subset of your instances gradually, monitor them and even automatically revert the deployment if you see that it has a negative effect on your key metrics.

Change Management – Rolling Deployment
Another solution could be that you run two production environments. You always deploy to only one of them, and you only point your load balancer to the new one after you verified that the new version works as it is expected. This is called blue-green, or red-black deployment.
Reverting code is not a bad thing. You shouldn’t leave broken code in production and then think about what went wrong. Always revert your changes when it’s necessary. The sooner the better.
Health-check and Load Balancing
Instances continuously start, restart and stop because of failures, deployments or autoscaling. It makes them temporarily or permanently unavailable. To avoid issues, your load balancer should skip unhealthy instances from the routing as they cannot serve your customers’ or sub-systems’ need.
Application instance health can be determined via external observation. You can do it with repeatedly calling a GET /healthendpoint or via self-reporting. Modern service discovery solutions continuously collect health information from instances and configure the load-balancer to route traffic only to healthy components.
Self-healing
Self-healing can help to recover an application. We can talk about self-healing when an application can do the necessary steps to recover from a broken state. In most of the cases, it is implemented by an external system that watches the instances health and restarts them when they are in a broken state for a longer period. Self-healing can be very useful in most of the cases, however, in certain situations it can cause trouble by continuously restarting the application. This might happen when your application cannot give positive health status because it is overloaded or its database connection timeouts.
Implementing an advanced self-healing solution which is prepared for a delicate situation – like a lost database connection – can be tricky. In this case, you need to add extra logic to your application to handle edge cases and let the external system know that the instance is not needed to restart immediately.
Failover Caching
Services usually fail because of network issues and changes in our system. However, most of these outages are temporary thanks to self-healing and advanced load-balancing we should find a solution to make our service work during these glitches. This is where failover caching can help and provide the necessary data to our application.
Failover caches usually use two different expiration dates; a shorter that tells how long you can use the cache in a normal situation, and a longer one that says how long can you use the cached data during failure.
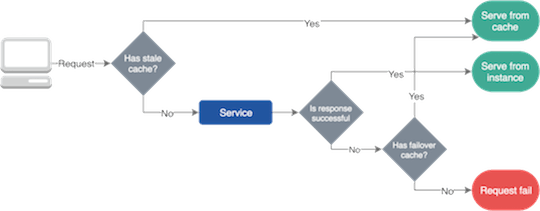
Failover Caching
It’s important to mention that you can only use failover caching when it serves the outdated data better than nothing.
To set cache and failover cache, you can use standard response headers in HTTP.
For example, with the max-age header you can specify the maximum amount of time a resource will be considered fresh. With the stale-if-error header, you can determine how long should the resource be served from a cache in the case of a failure.
Modern CDNs and load balancers provide various caching and failover behaviors, but you can also create a shared library for your company that contains standard reliability solutions.
Retry Logic
There are certain situations when we cannot cache our data or we want to make changes to it, but our operations eventually fail. In these cases, we can retry our action as we can expect that the resource will recover after some time or our load-balancer sends our request to a healthy instance.
You should be careful with adding retry logic to your applications and clients, as a larger amount of retries can make things even worse or even prevent the application from recovering.
In distributed system, a microservices system retry can trigger multiple other requests or retries and start a cascading effect. To minimize the impact of retries, you should limit the number of them and use an exponential backoff algorithm to continually increase the delay between retries until you reach the maximum limit.
As a retry is initiated by the client (browser, other microservices, etc.)and the client doesn’t know that the operation failed before or after handling the request, you should prepare your application to handle idempotency. For example, when you retry a purchase operation, you shouldn’t double charge the customer. Using a unique idempotency-key for each of your transactions can help to handle retries.
Rate Limiters and Load Shedders
Rate limiting is the technique of defining how many requests can be received or processed by a particular customer or application during a timeframe. With rate limiting, for example, you can filter out customers and microservices who are responsible for traffic peaks, or you can ensure that your application doesn’t overload until autoscaling can’t come to rescue.
You can also hold back lower-priority traffic to give enough resources to critical transactions.

A rate limiter can hold back traffic peaks
A different type of rate limiter is called the concurrent request limiter. It can be useful when you have expensive endpoints that shouldn’t be called more than a specified times, while you still want to serve traffic.
A fleet usage load shedder can ensure that there are always enough resources available to serve critical transactions. It keeps some resources for high priority requests and doesn’t allow for low priority transactions to use all of them. A load shedder makes its decisions based on the whole state of the system, rather than based on a single user’s request bucket size. Load shedders help your system to recover, since they keep the core functionalities working while you have an ongoing incident.
To read more about rate limiters and load shredders, I recommend checking out Stripe’s article.
Fail Fast and Independently
In a microservices architecture we want to prepare our services to fail fast and separately. To isolate issues on service level, we can use the bulkhead pattern. You can read more about bulkheads later in this blog post.
We also want our components to fail fast as we don’t want to wait for broken instances until they timeout. Nothing is more disappointing than a hanging request and an unresponsive UI. It’s not just wasting resources but also screwing up the user experience. Our services are calling each other in a chain, so we should pay an extra attention to prevent hanging operations before these delays sum up.
The first idea that would come to your mind would be applying fine grade timeouts for each service calls. The problem with this approach is that you cannot really know what’s a good timeout value as there are certain situations when network glitches and other issues happen that only affect one-two operations. In this case, you probably don’t want to reject those requests if there’s only a few of them timeouts.
We can say that achieving the fail fast paradigm in microservices by using timeouts is an anti-pattern and you should avoid it. Instead of timeouts, you can apply the circuit-breaker pattern that depends on the success / fail statistics of operations.
Bulkheads
Bulkhead is used in the industry to partition a ship into sections, so that sections can be sealed off if there is a hull breach.
The concept of bulkheads can be applied in software development to segregate resources.
By applying the bulkheads pattern, we can protect limited resources from being exhausted. For example, we can use two connection pools instead of a shared on if we have two kinds of operations that communicate with the same database instance where we have limited number of connections. As a result of this client – resource separation, the operation that timeouts or overuses the pool won’t bring all of the other operations down.
One of the main reasons why Titanic sunk was that its bulkheads had a design failure, and the water could pour over the top of the bulkheads via the deck above and flood the entire hull.

Bulkheads in Titanic (they didn’t work)
Circuit Breakers
To limit the duration of operations, we can use timeouts. Timeouts can prevent hanging operations and keep the system responsive. However, using static, fine tuned timeouts in microservices communication is an anti-pattern as we’re in a highly dynamic environment where it’s almost impossible to come up with the right timing limitations that work well in every case.
Instead of using small and transaction-specific static timeouts, we can use circuit breakers to deal with errors. Circuit breakers are named after the real world electronic component because their behavior is identical. You can protect resources and help them to recover with circuit breakers. They can be very useful in a distributed system where a repetitive failure can lead to a snowball effect and bring the whole system down.
A circuit breaker opens when a particular type of error occurs multiple times in a short period. An open circuit breaker prevents further requests to be made – like the real one prevents electrons from flowing. Circuit breakers usually close after a certain amount of time, giving enough space for underlying services to recover.
Keep in mind that not all errors should trigger a circuit breaker. For example, you probably want to skip client side issues like requests with 4xx response codes, but include 5xx server-side failures. Some circuit breakers can have a half-open state as well. In this state, the service sends the first request to check system availability, while letting the other requests to fail. If this first request succeeds, it restores the circuit breaker to a closed state and lets the traffic flow. Otherwise, it keeps it open.

Circuit Breaker
Testing for Failures
You should continually test your system against common issues to make sure that your services can survive various failures. You should test for failures frequently to keep your team prepared for incidents.
For testing, you can use an external service that identifies groups of instances and randomly terminates one of the instances in this group. With this, you can prepare for a single instance failure, but you can even shut down entire regions to simulate a cloud provider outage.
One of the most popular testing solutions is the ChaosMonkeyresiliency tool by Netflix.