Source: searchapparchitecture.techtarget.com
When user demand hits unexpected and sustained highs, an application’s scalability and fault tolerance are put to the test. Architects are learning that lesson even quicker as the COVID-19 pandemic pushes demand for distributed applications, forcing them to make big decisions about how they manage availability.
Microservices enable more efficient scaling than monolithic app architectures, because only the components experiencing higher demand need to ramp up with more instances. Resource consumption still grows, but without the waste common to monolith scaling. Organizations can improve the elasticity and resilience of monolithic applications by refactoring user-facing components to microservices, leaving the steady-use components in a functional monolith.
But maintaining high availability for microservices is not a simple task. To scale microservices with user demand, read these expert tips on growth scales and replication methods, basics of load balancing and API gateways. Ensure microservices’ high availability with a focus on caching for fast performance even under high loads, and monitoring that enables quick problem resolution.
The need for microservices scaling
Application architects often scale applications in three ways, known as x-axis, y-axis and z-axis scaling (the following image shows a scale cube devised by AKF Partners). X-axis scaling involves cloning service instances, which then reside behind a load balancer. Y-axis involves functional decompression, which refines granularity to help individual services scale independently in response to demands. Finally, in z-axis scaling, developers assign particular subsets of replicated data to servers designated only to handle that particular subset of data and route information accordingly.
Y-axis scaling is directly associated with designing highly available microservices, since it requires developers to appropriately segment services that scale independently. But due to global changes surrounding how people work, learn and play online, the z-axis can now also play a big part in microservices fault tolerance. Since z-axis scaling focuses on splitting servers based on qualities such as geographic location or customer IDs, it becomes much easier to identify and isolate faults that may otherwise cause cascading failures across all services.
But scaling methods aren’t the end of an architect’s decisions, as there are still decisions to make around monitoring, tracing and resource allocations. Joydip Kanjilal, software architect and technical advisor, explains more about these issues in a previously published article on microservices scaling skills.
Service-to-service load balancing
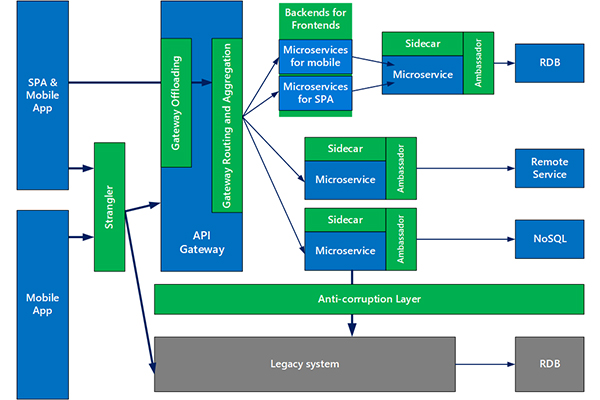
Developers who are more familiar with monolithic architectures will find that load balancing is a different animal when it comes to microservices. This is because communication in a microservices architecture occurs service-to-service, as opposed to client-to-server. Because of this, developers now look to new load-balancing tools and techniques that appropriately distribute workloads across many services simultaneously.
One load balancing technique that emerged for microservices high availability is the API gateway. This is a component that acts as a single point of entry and distribution for application traffic, acting as a connection point for independent components. Client requests are sent to the gateway, which receives these requests as an API call. It then creates another API call that delegates the request to the appropriate service or services. API gateways can also manage translations and protocols between pieces of software.
Twain Taylor, technology analyst, wrote an article that examines more about these techniques and how service-to-service communication affects load balancing, including a review of cloud-native and third-party tools designed to handle service-to-service communication.
Built-in data caching
A critical consideration for microservices high availability is performance, not simply whether the app is up or down. To maintain high performance under heavy load, design the application with caching built in.
Data caching keeps information from a database server ready whenever a microservice needs it. Caching can also mask an outage by making the data available whether or not the originating service is up. Kanjilal breaks down two types of caches — preloaded and lazy loaded — in another article written for microservices adopters. He also explains ways to optimize resources and scale microservices with shared caches.
Monitoring and tracing for issues
No matter how thoroughly you design microservices for high availability, you must deploy monitoring tailored specifically for your application architecture in order to catch problems that could degrade user experience.
Microservices complicate monitoring. Unlike monolithic app deployments, distributed services execute simultaneously, and a single action can call upon multiple services. As such, this architecture style inherently obscures failure points, since it becomes exponentially more complex to identify a single point of failure.
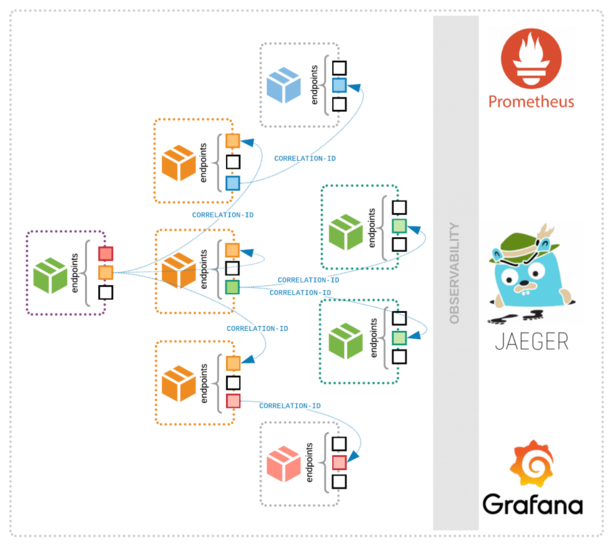
To combat this, set up semantic monitoring and distributed tracing that provides a clearer picture of service availability and health. Semantic monitoring, also known as synthetic transaction monitoring, tests business transaction functionality, service availability and overall application performance from the user perspective.
Distributed tracing is another technique that monitors the path a request takes through each module or service instance, even if it travels across dispersed replica instances and multiple calls. This helps application support teams pinpoint failures and performance bottlenecks — a key part of microservices high availability. Developers should learn as much as they can about how distributed tracing works and the tools that help.