Introduction
Document Ingestion & Chunking Pipelines are a core layer of modern AI systems that power Retrieval-Augmented Generation (RAG), semantic search, enterprise copilots, and AI agents. These pipelines take raw, unstructured documents—such as PDFs, web pages, Word files, spreadsheets, emails, and scanned images—and convert them into clean, structured, and optimally segmented chunks that can be embedded and retrieved efficiently.
In simple terms, ingestion pipelines handle “getting data in,” while chunking pipelines decide “how to break it into meaningful pieces” so AI models can understand and retrieve context accurately. Poor chunking leads to hallucinations, irrelevant retrieval, and degraded AI performance, while well-designed pipelines significantly improve accuracy, latency, and cost efficiency.
These tools are now essential for enterprise AI platforms, knowledge assistants, customer support bots, legal discovery systems, healthcare intelligence platforms, and any system using vector databases or LLM-based retrieval.
Evaluation Criteria for Buyers
When evaluating document ingestion and chunking pipelines, consider:
- Document parsing accuracy (PDF, HTML, OCR, etc.)
- Chunking strategies (semantic, hierarchical, sliding window)
- Metadata extraction quality
- Support for multimodal content (tables, images, charts)
- Integration with vector databases
- RAG compatibility
- Real-time ingestion capability
- Scalability and throughput
- Customization of chunking logic
- Observability and debugging tools
- Security and data privacy controls
- API and SDK availability
Best for: AI engineering teams, RAG developers, enterprise search platforms, SaaS companies, and organizations building LLM-powered knowledge systems.
Not ideal for: Simple static websites, non-AI systems, or applications that do not require semantic retrieval or embeddings.
What’s Changed in Document Ingestion & Chunking Pipelines
- Shift from fixed chunking to semantic and LLM-driven chunking
- Emergence of agentic ingestion pipelines with self-correcting parsing
- Multimodal ingestion (text + images + tables + audio transcripts)
- Real-time streaming document ingestion for live AI systems
- Adaptive chunk sizing based on embedding density
- Integration with GraphRAG and knowledge graph systems
- Context-aware chunk merging and splitting
- Built-in evaluation of retrieval effectiveness per chunk
- Metadata-rich chunk generation for better filtering
- Automatic structure detection in unstructured documents
- Stronger privacy and data governance controls
- Native integration with vector databases and embedding pipelines
Quick Buyer Checklist
- Supports PDF, DOCX, HTML, JSON, and OCR inputs
- Provides multiple chunking strategies (semantic + structural)
- Maintains metadata during ingestion
- Integrates with vector databases (Pinecone, Weaviate, etc.)
- Supports real-time ingestion pipelines
- Offers API/SDK for customization
- Handles multimodal document formats
- Provides observability for ingestion quality
- Allows configurable chunk size and overlap
- Supports LLM-based parsing enhancements
- Ensures data privacy and encryption
- Minimizes vendor lock-in
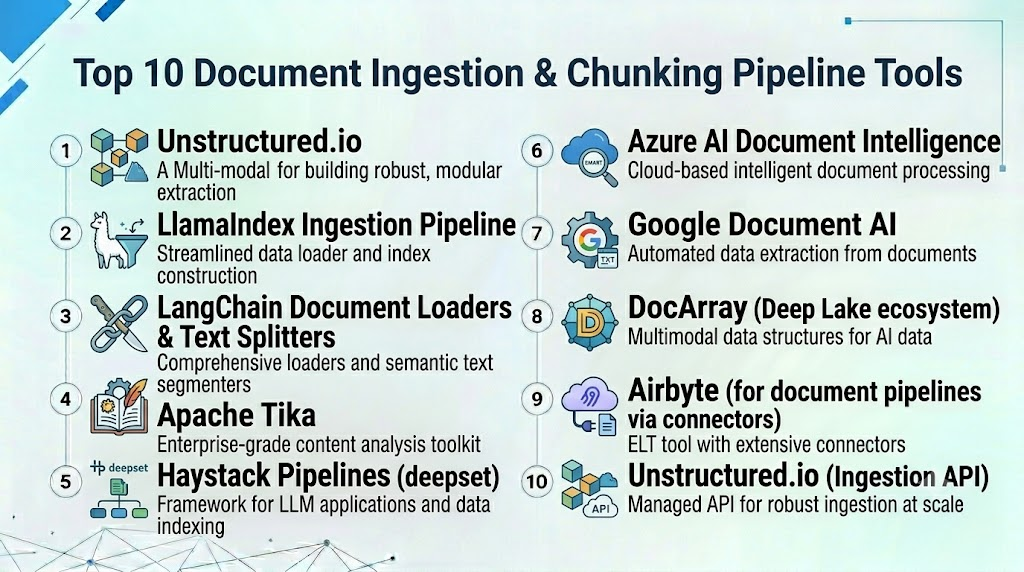
Top 10 Document Ingestion & Chunking Pipeline Tools
1- Unstructured.io
One-line verdict: Best end-to-end document ingestion and chunking platform for enterprise RAG pipelines.
Short description:
Unstructured.io is a widely used pipeline for converting raw enterprise documents into structured, chunked data optimized for LLMs and vector databases.
Standout Capabilities
- Advanced document parsing (PDF, HTML, DOCX, emails)
- Intelligent chunking strategies
- Metadata extraction
- Table and layout recognition
- OCR support for scanned documents
- RAG-ready output formatting
- API-first ingestion pipeline
AI-Specific Depth
- Model support: Works with any embedding/LLM model
- RAG integration: Native-first design
- Evaluation: Not publicly stated
- Guardrails: Basic data filtering and sanitization
- Observability: Ingestion logs and structured outputs
Pros
- Highly optimized for RAG workflows
- Strong document parsing accuracy
- Easy integration with vector databases
Cons
- Some advanced features require enterprise plan
- Limited control over deep parsing internals
- Cloud dependency for managed service
Deployment & Platforms
- Cloud API
- Self-hosted options available
- Hybrid deployments
Integrations & Ecosystem
Works with LangChain, LlamaIndex, vector databases, and major LLM frameworks.
Pricing Model
Usage-based and enterprise licensing (varies / not fully publicly stated).
Best-Fit Scenarios
- Enterprise RAG pipelines
- AI knowledge assistants
- Document intelligence systems
2- LlamaIndex Ingestion Pipeline
One-line verdict: Best developer-first framework for RAG ingestion and chunking workflows.
Short description:
LlamaIndex provides a flexible ingestion and chunking framework designed for building LLM applications with structured retrieval pipelines.
Standout Capabilities
- Modular ingestion pipeline
- Multiple chunking strategies
- Document connectors (PDF, APIs, web)
- Metadata enrichment
- Vector store integration
- Query-aware indexing
- Hierarchical chunking
AI-Specific Depth
- Model support: Multi-LLM compatible
- RAG integration: Native core functionality
- Evaluation: Built-in evaluation modules
- Guardrails: Basic pipeline constraints
- Observability: Tracing and debugging tools
Pros
- Highly flexible architecture
- Strong developer ecosystem
- Excellent RAG tooling
Cons
- Requires engineering effort
- Not a turnkey enterprise system
- Performance tuning needed at scale
Deployment & Platforms
- Python-based library
- Cloud and local deployment
Integrations & Ecosystem
Integrates with OpenAI, Hugging Face, vector databases, and orchestration tools.
Pricing Model
Open-source.
Best-Fit Scenarios
- RAG application development
- AI prototypes and production pipelines
- Custom ingestion workflows
3- LangChain Document Loaders & Text Splitters
One-line verdict: Best ecosystem-driven ingestion framework for LLM applications.
Short description:
LangChain provides document loaders and chunking utilities for building AI applications with structured ingestion pipelines.
Standout Capabilities
- Document loaders (PDF, web, APIs)
- Text splitting strategies
- Chunk metadata handling
- Integration with vector stores
- LLM-based preprocessing
- Streaming ingestion support
- Modular pipeline design
AI-Specific Depth
- Model support: Multi-model compatible
- RAG integration: Core design principle
- Evaluation: External tooling required
- Guardrails: Basic pipeline-level controls
- Observability: LangSmith integration
Pros
- Huge ecosystem support
- Flexible ingestion components
- Strong community adoption
Cons
- Not a standalone ingestion system
- Requires integration effort
- Can become complex in large pipelines
Deployment & Platforms
- Library-based (Python/JS)
- Cloud + local
Integrations & Ecosystem
Works with vector databases, LLM APIs, and orchestration frameworks.
Pricing Model
Open-source core with optional paid observability tools.
Best-Fit Scenarios
- LLM application pipelines
- RAG workflows
- Custom ingestion logic
4- Apache Tika
One-line verdict: Best open-source document parsing engine for raw content extraction.
Short description:
Apache Tika is a robust content extraction toolkit that detects and extracts text and metadata from a wide range of file formats.
Standout Capabilities
- Multi-format document parsing
- Metadata extraction
- Language detection
- OCR support (via extensions)
- MIME type detection
- Scalable processing
- Java-based architecture
AI-Specific Depth
- Model support: External only
- RAG integration: Requires pipeline layering
- Evaluation: Not available
- Guardrails: None built-in
- Observability: Logging only
Pros
- Extremely reliable parsing engine
- Supports many file formats
- Mature open-source project
Cons
- Not AI-native
- Requires integration work
- No chunking intelligence
Deployment & Platforms
- Self-hosted
- Java-based runtime
Best-Fit Scenarios
- Raw document ingestion
- Enterprise content extraction
- Preprocessing pipelines
5- Haystack Pipelines (deepset)
One-line verdict: Best full-stack RAG pipeline framework with strong ingestion capabilities.
Short description:
Haystack provides end-to-end pipelines for document ingestion, preprocessing, chunking, retrieval, and generation.
Standout Capabilities
- Modular pipeline design
- Document preprocessing
- Semantic chunking
- Retriever + generator integration
- OCR and parsing support
- Metadata handling
- Production-ready workflows
AI-Specific Depth
- Model support: Multi-LLM compatible
- RAG integration: Native support
- Evaluation: Built-in evaluation framework
- Guardrails: Pipeline-level controls
- Observability: Debugging and tracing
Pros
- Production-ready architecture
- Strong RAG focus
- Modular and scalable
Cons
- Learning curve
- Requires pipeline design effort
- Complex setup for beginners
Deployment & Platforms
- Cloud
- Self-hosted
- Hybrid
Integrations & Ecosystem
Supports vector databases, LLM providers, and enterprise tools.
Pricing Model
Open-source core + enterprise offering.
Best-Fit Scenarios
- Enterprise RAG systems
- AI search pipelines
- Production LLM applications
6- Azure AI Document Intelligence
One-line verdict: Best enterprise-grade document ingestion system for structured extraction.
Short description:
Azure AI Document Intelligence extracts structured data from documents using advanced AI and OCR models.
Standout Capabilities
- OCR-based extraction
- Form and table recognition
- Structured data parsing
- Prebuilt AI models
- Enterprise security integration
- Scalable cloud processing
- Multilingual support
AI-Specific Depth
- Model support: Microsoft pre-trained models
- RAG integration: Via Azure AI Search pipelines
- Evaluation: Not publicly stated
- Guardrails: Enterprise compliance controls
- Observability: Azure monitoring tools
Pros
- Highly accurate extraction
- Enterprise-ready
- Strong Azure integration
Cons
- Azure dependency
- Less flexibility in customization
- Cost increases with scale
Deployment & Platforms
- Cloud only (Azure)
Best-Fit Scenarios
- Enterprise document automation
- Invoice and form processing
- AI data extraction pipelines
7- Google Document AI
One-line verdict: Best AI-powered document parsing system for structured extraction at scale.
Short description:
Google Document AI converts unstructured documents into structured data using advanced ML models.
Standout Capabilities
- Pre-trained document parsers
- Form and invoice extraction
- Table detection
- OCR engine
- Scalable processing
- Multimodal document support
- Enterprise integration
AI-Specific Depth
- Model support: Google ML models
- RAG integration: Via Vertex AI pipelines
- Evaluation: Not publicly stated
- Guardrails: Google Cloud IAM
- Observability: Cloud logging
Pros
- High extraction accuracy
- Scalable cloud service
- Strong AI models
Cons
- Google Cloud dependency
- Limited customization
- Pricing complexity
Deployment & Platforms
- Cloud only (GCP)
Best-Fit Scenarios
- Enterprise document automation
- Large-scale ingestion systems
- AI data extraction
8- DocArray (Deep Lake ecosystem)
One-line verdict: Best for multimodal document ingestion and AI dataset preparation.
Short description:
DocArray focuses on structuring multimodal data for AI systems, including text, images, audio, and embeddings.
Standout Capabilities
- Multimodal document handling
- Embedding storage
- Dataset versioning
- AI pipeline integration
- Chunk metadata management
- Structured data representation
- Vector compatibility
AI-Specific Depth
- Model support: Embedding-agnostic
- RAG integration: Strong support
- Evaluation: External tools required
- Guardrails: None built-in
- Observability: Dataset tracking
Pros
- Excellent for multimodal AI
- Flexible architecture
- Strong dataset handling
Cons
- Not a full ingestion platform
- Requires integration
- Smaller ecosystem
Deployment & Platforms
- Library-based
- Cloud + local
Best-Fit Scenarios
- Multimodal AI systems
- Dataset preparation pipelines
- RAG ingestion workflows
9- Airbyte (for document pipelines via connectors)
One-line verdict: Best data ingestion platform extended for document pipeline integration.
Short description:
Airbyte provides connectors for ingesting structured and semi-structured data into AI systems, including document sources via integrations.
Standout Capabilities
- Connector-based ingestion
- Pipeline automation
- Data normalization
- Batch and streaming ingestion
- Extensible architecture
- API-first design
- ETL/ELT workflows
AI-Specific Depth
- Model support: External systems
- RAG integration: Indirect via pipelines
- Evaluation: Not available
- Guardrails: Pipeline-level controls
- Observability: Sync monitoring
Pros
- Highly extensible
- Strong connector ecosystem
- Open-source core
Cons
- Not AI-native ingestion
- Requires customization for chunking
- Limited document intelligence
Deployment & Platforms
- Cloud
- Self-hosted
Best-Fit Scenarios
- Data ingestion pipelines
- Enterprise ETL for AI systems
- Structured ingestion workflows
10- Unstructured.io (Ingestion API)
One-line verdict: Best end-to-end document-to-chunk pipeline for LLM applications.
Short description:
Unstructured.io specializes in converting raw documents into structured chunks optimized for embedding and retrieval.
Standout Capabilities
- Advanced document parsing
- Semantic chunking
- Layout detection
- OCR support
- Metadata enrichment
- RAG-ready outputs
- API-first ingestion
AI-Specific Depth
- Model support: Model-agnostic
- RAG integration: Native-first design
- Evaluation: Not publicly stated
- Guardrails: Basic data filtering
- Observability: Ingestion logs
Pros
- Highly optimized for RAG
- Strong parsing accuracy
- Easy integration
Cons
- Some features enterprise-only
- Limited customization depth
- Dependency on API for full features
Deployment & Platforms
- Cloud API
- Self-hosted (limited)
Best-Fit Scenarios
- RAG ingestion pipelines
- Enterprise document AI
- Knowledge base construction
Comparison Table
| Tool | Best For | Deployment | Model Flexibility | Strength | Watch-Out | Public Rating |
|---|---|---|---|---|---|---|
| Unstructured.io | RAG pipelines | Cloud/Hybrid | High | Chunking quality | API dependency | N/A |
| LlamaIndex | Developer RAG | Library | High | Flexibility | Engineering effort | N/A |
| LangChain | LLM pipelines | Library | High | Ecosystem | Complexity | N/A |
| Apache Tika | Parsing engine | Self-hosted | High | Format support | No AI logic | N/A |
| Haystack | RAG pipelines | Hybrid | High | End-to-end system | Learning curve | N/A |
| Azure Document Intelligence | Enterprise extraction | Cloud | Medium | OCR accuracy | Azure lock-in | N/A |
| Google Document AI | Cloud extraction | Cloud | Medium | ML accuracy | GCP lock-in | N/A |
| DocArray | Multimodal AI | Hybrid | High | Multimodal support | Limited ecosystem | N/A |
| Airbyte | Data ingestion | Hybrid | High | Connectors | Not AI-native | N/A |
| Unstructured.io API | Chunking pipeline | Cloud/API | High | RAG optimization | API dependency | N/A |
Scoring & Evaluation
| Tool | Core | Reliability | Guardrails | Integrations | Ease | Performance | Security | Support | Weighted Total |
|---|---|---|---|---|---|---|---|---|---|
| Unstructured.io | 10 | 9 | 8 | 10 | 9 | 9 | 8 | 9 | 9.1 |
| LlamaIndex | 9 | 9 | 8 | 10 | 9 | 8 | 7 | 8 | 8.6 |
| LangChain | 9 | 8 | 7 | 10 | 9 | 8 | 7 | 8 | 8.3 |
| Apache Tika | 8 | 9 | 6 | 8 | 7 | 9 | 8 | 8 | 8.0 |
| Haystack | 9 | 9 | 9 | 9 | 7 | 9 | 8 | 8 | 8.7 |
| Azure Document Intelligence | 9 | 9 | 9 | 9 | 8 | 9 | 10 | 9 | 9.0 |
| Google Document AI | 9 | 9 | 8 | 9 | 8 | 9 | 9 | 8 | 8.8 |
| DocArray | 8 | 8 | 7 | 9 | 8 | 8 | 8 | 8 | 8.1 |
| Airbyte | 8 | 8 | 7 | 9 | 8 | 8 | 8 | 8 | 8.0 |
| Unstructured API | 9 | 9 | 8 | 9 | 9 | 9 | 8 | 9 | 8.9 |
Conclusion
Document Ingestion & Chunking Pipelines are now a critical foundation for AI systems built on RAG, semantic search, and agent-based architectures. The quality of ingestion directly determines retrieval accuracy, latency, and LLM performance. As AI systems evolve, these pipelines are becoming more intelligent, adaptive, and tightly integrated with vector databases and knowledge graphs.