Introduction
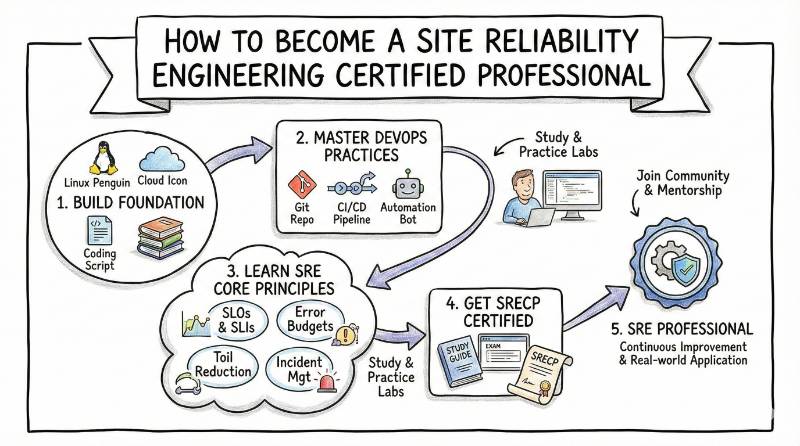
Site Reliability Engineering (SRE) is a discipline that applies software engineering principles to IT operations, ensuring scalable, reliable, and efficient systems. As cloud computing and microservices become integral to modern software development, SRE plays a crucial role in making sure systems are resilient, available, and performant.The Site Reliability Engineering Certified Professional (SRECP) certification is designed to help professionals acquire the skills required to become experts in managing and optimizing cloud infrastructure, automation, and incident response. This certification validates that a professional can ensure systems run smoothly at scale, with minimal downtime and optimal performance.
What is SRECP?
The SRECP certification validates an individual’s ability to manage large-scale, distributed systems effectively. It equips professionals with the expertise to implement best practices for monitoring, incident management, automation, and system reliability. The certification is an ideal choice for those in DevOps, cloud, or platform engineering roles, providing the credentials required to handle high-availability services in modern IT environments.
Who Should Take SRECP?
The SRECP certification is designed for professionals working in various fields of IT and operations. Ideal candidates include:
- DevOps Engineers who want to specialize in system reliability.
- Cloud Engineers and Platform Engineers who manage cloud-based infrastructure.
- Site Reliability Engineers (SREs) seeking formal certification to prove their expertise.
- System Administrators and IT Managers aiming to transition to an SRE role or enhance their skills.
Skills You’ll Gain from SRECP
By completing the SRECP certification, you will acquire a variety of skills crucial to maintaining and scaling modern systems:
- Monitoring & Incident Management: Learn how to set up monitoring systems to track the performance of applications and services.
- Service-Level Objectives (SLOs): Master the creation of SLOs to measure system reliability and define performance standards.
- Automation: Gain practical knowledge of automating repetitive tasks using tools like Jenkins, Kubernetes, and Terraform to improve efficiency.
- System Design & Scalability: Understand how to design systems that are capable of handling increasing demand without degradation in performance.
- Resilience Engineering & Disaster Recovery: Learn to create disaster recovery plans and build resilient systems that recover quickly from failures.
- Capacity Planning & Cost Optimization: Understand how to balance system performance with cost, ensuring efficient resource allocation.
Competence Table:
| Competence Area | Description | Skills Involved | Tools | Key Metrics |
|---|---|---|---|---|
| Monitoring & Incident Management | Design, implement, and manage monitoring systems that ensure system uptime and performance. | SLIs, SLOs, error budgets, alerting systems | Prometheus, Grafana, Datadog | Uptime, incident response time, availability |
| Automation | Automating repetitive operational tasks to reduce manual interventions. | Scripting, CI/CD automation, infrastructure as code | Jenkins, Kubernetes, Terraform | Deployment frequency, automation success rate |
| System Scalability & Design | Designing systems that are scalable, performant, and resilient under heavy traffic or failure conditions. | Load balancing, fault tolerance, horizontal scaling | AWS, Azure, Kubernetes | Throughput, latency, cost efficiency |
| Resilience Engineering | Creating systems that remain available and functional during failure events or disaster scenarios. | Chaos engineering, disaster recovery planning | Gremlin, Chaos Monkey | Recovery time, fault tolerance |
| Capacity Planning & Cost Optimization | Managing resources and optimizing costs while maintaining reliability and scalability. | Resource allocation, scaling strategies | AWS Cost Explorer, Azure Cost Management | Resource utilization, cost savings |
| Collaboration & Leadership | Working with cross-functional teams and managing incident response teams to ensure the reliability of systems. | Team collaboration, cross-functional communication | Slack, Jira, PagerDuty | Team coordination, incident resolution time |
Real-World Projects You Should Be Able to Do After Completing SRECP
Upon completing the SRECP certification, you will be capable of handling several real-world scenarios, such as:
- Building and implementing monitoring systems for large-scale web applications using Prometheus and Grafana.
- Designing fault-tolerant systems that remain highly available and scalable using cloud platforms like AWS or Azure.
- Automating incident response processes using tools like Jenkins, Kubernetes, and Terraform to minimize human intervention and improve operational efficiency.
- Setting up disaster recovery systems to ensure business continuity even during major incidents.
- Optimizing system performance and cost by analyzing and adjusting cloud resources based on real-time demand.
Preparation Plan for SRECP Certification
7-14 Days Preparation Plan (For Limited Time)
For those with limited time, this plan covers the core principles and key areas required for the SRECP certification.
Day 1-3: Introduction to SRE and Key Concepts
- Understand SLIs, SLOs, and error budgets.
- Familiarize yourself with the SRE model and its benefits.
- Learn about monitoring and incident management fundamentals.
Day 4-6: Automation and Basic Incident Management
- Focus on automation tools like Terraform, Jenkins, and Kubernetes.
- Learn how to set up monitoring tools like Prometheus.
- Practice basic incident response procedures.
Day 7-14: System Design and Resilience Engineering
- Study scalable system design concepts.
- Learn to build fault-tolerant systems with redundancy.
- Explore disaster recovery strategies and their implementation.
30 Days Preparation Plan (For Moderate Time)
This plan provides a deeper dive into SRE practices, suitable for professionals with 30 days to prepare.
Week 1: Core Concepts & Monitoring
- Study SLIs, SLOs, and error budgets in-depth.
- Install Prometheus and Grafana, and learn how to configure them for real-time monitoring.
- Focus on incident management and on-call strategies.
Week 2: Automation & Basic System Design
- Learn about automation tools like Jenkins, Kubernetes, and Terraform.
- Study basic system design principles for scalability and redundancy.
Week 3: Advanced System Design & Resilience Engineering
- Study high-availability architectures and load balancing techniques.
- Learn about disaster recovery practices and chaos engineering to improve system reliability.
Week 4: Review and Mock Exams
- Take practice exams and focus on areas that need improvement.
- Implement real-world scenarios to test your knowledge in a practical setting.
60 Days Preparation Plan (For Ample Time)
The 60-day plan offers a thorough preparation process with more hands-on practice, allowing for deeper mastery of SRE concepts.
Week 1-2: Core Concepts & SLOs
- Understand the foundational SRE principles: monitoring, incident management, and SLOs.
- Set up and configure Prometheus, Grafana, and PagerDuty for incident management.
Week 3-4: System Design and Scalability
- Dive into scalable system design, focusing on building distributed systems with load balancing and auto-scaling.
- Study resilience engineering techniques and tools.
Week 5-6: Automation & Disaster Recovery
- Focus on automating deployments and monitoring with tools like Terraform and Jenkins.
- Learn about disaster recovery, capacity planning, and cost optimization in cloud environments.
Week 7-8: Review, Hands-on Practice & Mock Exams
- Implement real-world projects based on SRE principles.
- Take multiple practice exams and review any weak areas.
Common Mistakes to Avoid
- Skipping foundational concepts like SLIs, SLOs, and incident management.
- Neglecting automation: Automation is key to SRE, so ensure you dedicate enough time to mastering it.
- Ignoring incident management practices: Incident resolution is one of the core responsibilities of SREs.
- Not practicing enough hands-on: Theory alone isn’t enough; practical application is essential.
Best Next Certifications After SRECP
- Same Track:
- Certified Site Reliability Engineer (CSRE): An advanced certification focusing on high-level SRE strategies.
- Cross-Track:
- DevOps Certified Professional (DCP): This certification complements SRE principles and extends to the broader DevOps pipeline.
- Leadership:
- Certified DevOps Manager (CDM): For those looking to transition to leadership roles, this certification focuses on managing SRE and DevOps teams.
Choose Your Path: 6 Learning Paths
1. DevOps
Learn the full scope of DevOps practices, focusing on automation, infrastructure management, and continuous integration.
2. DevSecOps
Dive into security practices integrated into the DevOps pipeline, ensuring secure software development from the start.
3. SRE
Specialize in Site Reliability Engineering, learning to manage, monitor, and scale reliable systems in production environments.
4. AIOps/MLOps
Leverage AI and machine learning for IT operations and system reliability, using advanced technologies to improve performance and automate incident management.
5. DataOps
Focus on the management and reliability of data systems, ensuring efficient data pipelines, governance, and availability.
6. FinOps
Learn cloud financial operations, focusing on optimizing cloud costs, budgeting, and forecasting within organizations.
Role → Recommended Certifications
| Role | Recommended Certifications |
|---|---|
| DevOps Engineer | DCP, SRECP, CSRE |
| SRE | SRECP, CSRE, DCP |
| Platform Engineer | DCP, SRECP, DevOps Architect |
| Cloud Engineer | Cloud Certification, SRECP |
| Security Engineer | DevSecOps Certified Professional, SRECP |
| Data Engineer | DataOps Certified Professional, SRECP |
| FinOps Practitioner | FinOps Certified Professional, SRECP |
| Engineering Manager | CDM, SRECP |
Top Institutions Offering Training for SRECP
1. DevOpsSchool
DevOpsSchool offers comprehensive training in Site Reliability Engineering, focusing on practical applications, hands-on labs, and live instructor-led sessions. They help candidates master SRE tools and concepts for the SRECP certification.
2. Cotocus
Cotocus provides specialized SRE training, emphasizing real-world projects and practical scenarios. Their courses are designed to help professionals gain the skills required for the SRECP exam.
3. Scmgalaxy
Scmgalaxy offers detailed SRE training, covering all aspects of SRE principles, from monitoring to automation. Their courses are industry-focused, providing practical knowledge to ensure candidates pass the certification exam.
4. BestDevOps
BestDevOps provides hands-on SRE training, focusing on cloud-native applications and reliability engineering. Their certification programs are tailored to help candidates develop expertise in scaling and managing resilient systems.
5. DevSecOpsSchool
DevSecOpsSchool combines SRE with security, ensuring that SRE principles are applied securely in the DevOps pipeline. This approach prepares candidates to handle system reliability while integrating security practices.
6. SRESchool
SRESchool offers dedicated Site Reliability Engineering training, focusing on ensuring highly available and scalable systems. Their curriculum is designed to equip professionals with all the skills required for the SRECP exam.
7. AIOpsSchool
AIOpsSchool offers a combination of SRE and AI, teaching professionals how to automate and manage complex systems using machine learning for IT operations and incident management.
8. DataOpsSchool
DataOpsSchool focuses on building resilient data systems and pipelines. Their SRE training ensures that professionals can handle data reliability at scale, making them perfect candidates for the SRECP certification.
9. FinOpsSchool
FinOpsSchool teaches cloud cost optimization alongside SRE practices, ensuring that professionals can manage resources efficiently while maintaining system reliability.
General FAQs (12 Questions)
1. How difficult is the SRECP exam?
The SRECP exam is considered to be intermediate to advanced in difficulty. It requires practical knowledge and application of Site Reliability Engineering (SRE) principles such as incident management, automation, monitoring, and system scalability. Candidates should be prepared for scenario-based questions that test both theoretical understanding and hands-on skills.
2. How long does it take to prepare for the SRECP certification?
Typically, preparation for the SRECP certification can take anywhere between 2-3 months for professionals with foundational knowledge in IT operations. If you’re new to the concepts, dedicating 60 days will help ensure a deeper understanding of SRE principles.
3. What are the prerequisites for the SRECP certification?
To pursue the SRECP certification, candidates should have a basic understanding of cloud technologies (AWS, Azure, Google Cloud), Linux systems, and experience with monitoring tools like Prometheus or Grafana. Previous experience in DevOps, system administration, or IT operations will be beneficial but is not mandatory.
4. What is the sequence of topics covered in the SRECP certification?
The SRECP certification covers a wide range of topics in a structured order:
- Introduction to SRE: SRE principles, SLIs, SLOs, and error budgets.
- Monitoring and Incident Management: Tools and techniques for effective monitoring and incident handling.
- Automation: Automation of repetitive tasks such as deployments and scaling.
- System Design and Scalability: Building scalable, resilient systems for modern cloud environments.
- Resilience Engineering and Disaster Recovery: Designing systems that remain available under failure conditions.
- Cost Optimization and Capacity Planning: Managing resource usage efficiently while maintaining reliability.
5. What is the value of obtaining the SRECP certification?
The SRECP certification helps professionals validate their expertise in ensuring the reliability, scalability, and efficiency of modern IT systems. It enhances your professional credibility, improves job prospects, and allows you to apply best practices in managing and automating cloud systems. This certification is highly regarded by top tech companies and is an investment in your career.
6. What career outcomes can I expect after obtaining the SRECP certification?
With the SRECP certification, professionals can advance to roles such as:
- Site Reliability Engineer (SRE)
- Cloud Engineer
- DevOps Engineer
- Platform Engineer
- Infrastructure Architect
The certification also positions you for leadership roles in managing and scaling large-scale systems and infrastructure, including Engineering Manager positions.
7. How does the SRECP certification impact my salary?
Obtaining the SRECP certification can significantly boost your earning potential. SRE professionals are in high demand due to the increasing complexity of IT systems. Certified professionals typically earn more than their non-certified counterparts, and organizations value certified SREs for their ability to ensure the reliability and performance of critical systems.
8. What topics should I focus on for the SRECP exam?
To prepare effectively for the SRECP exam, focus on the following areas:
- SLIs, SLOs, and Error Budgets: These are key metrics in measuring and ensuring system reliability.
- Incident Management: Understanding how to detect, manage, and resolve incidents effectively.
- Automation and CI/CD: Practice automating deployments and system monitoring to ensure reliability.
- Scalability and Resilience: Understand how to build scalable systems with redundancy and fault tolerance.
- Disaster Recovery: Learn how to design systems that can recover quickly from failures.
9. How can I stay updated on SRE best practices and tools?
SRE best practices evolve constantly. To stay updated:
- Follow reputable SRE blogs and books (e.g., Google’s “Site Reliability Engineering” book).
- Join online communities like Reddit, Slack groups, and LinkedIn groups.
- Participate in webinars, online courses, and conferences related to SRE and DevOps.
- Continuously work on hands-on projects that require SRE practices and tools like Kubernetes, Prometheus, and Terraform.
10. What are the benefits of combining SRE with DevOps?
Combining SRE and DevOps practices offers several benefits:
- Improved collaboration between development and operations teams.
- Enhanced automation and scalability of systems.
- The ability to release features faster without sacrificing system reliability.
- Better resource utilization and cost optimization across both development and operations.
11. How do I balance feature development with system reliability?
The concept of error budgets in SRE helps balance system reliability with feature development. When error budgets (the acceptable level of failure) are exhausted, the focus shifts to improving reliability. This approach allows development teams to innovate while ensuring that system stability remains intact.
12. How can SRE help reduce downtime?
SRE helps reduce downtime by:
- Implementing effective monitoring to detect issues early.
- Automating incident resolution processes to minimize human error.
- Designing resilient systems that can continue to operate under failure conditions (e.g., using load balancing and failover strategies).
- Performing disaster recovery drills to ensure quick recovery during outages.
FAQs on Site Reliability Engineering Certified Professional (SRECP)
1. What is the SRECP certification?
The SRECP certification validates a professional’s expertise in Site Reliability Engineering, covering system design, automation, monitoring, incident management, and scaling.
2. Who should take the SRECP exam?
The certification is designed for DevOps Engineers, SREs, Cloud Engineers, and Platform Engineers who want to specialize in system reliability.
3. What are the prerequisites for the SRECP certification?
Candidates should have a basic understanding of cloud computing, Linux systems, and monitoring tools like Prometheus and Grafana.
4. How long does it take to prepare for the SRECP exam?
Preparation typically takes between 2-3 months, depending on your prior experience and familiarity with SRE principles.
5. How difficult is the SRECP exam?
The exam is intermediate to advanced in difficulty. Candidates are expected to demonstrate their practical knowledge of SRE concepts.
6. What are the career outcomes after obtaining the SRECP?
SRECP opens up various roles like Site Reliability Engineer, Cloud Engineer, DevOps Engineer, and Platform Engineer.
7. What is the next step after the SRECP certification?
After SRECP, candidates can pursue advanced certifications like Certified Site Reliability Engineer (CSRE) or explore DevOps and Cloud certifications.
8. Is the SRECP certification globally recognized?
Yes, SRECP is a globally recognized certification that validates skills in Site Reliability Engineering, making you an asset to organizations worldwide.
Conclusion
The SRECP certification is an essential credential for professionals aiming to specialize in Site Reliability Engineering. It equips you with the skills required to build, maintain, and optimize large-scale, reliable systems, ensuring high service availability. Whether you’re looking to enhance your career as an SRE, DevOps engineer, or cloud engineer, SRECP will provide the knowledge and recognition needed to succeed in modern IT operations.