Introduction
Bias & Fairness Testing Suites help teams identify, measure, and reduce unfair outcomes in AI and machine learning systems. These tools test whether models behave differently across user groups, languages, regions, demographics, data segments, or sensitive attributes. They are especially important for hiring, lending, insurance, healthcare, education, public services, customer support, and generative AI applications where biased decisions or responses can create legal, ethical, and reputational risk.
As AI systems become more autonomous, fairness testing is no longer limited to traditional ML models. Buyers now need tools that can evaluate LLM outputs, agent decisions, RAG responses, multimodal inputs, and production behavior over time.
Real-world use cases include:
- Testing hiring models for demographic bias
- Checking lending or insurance models for disparate impact
- Evaluating LLM responses for stereotypes and harmful assumptions
- Monitoring fairness drift after deployment
- Auditing AI systems for compliance and governance
- Comparing model behavior across languages, regions, and user groups
Evaluation criteria for buyers include fairness metrics, protected attribute handling, LLM bias testing, explainability, audit logs, monitoring, integrations, deployment flexibility, privacy controls, human review workflows, and ease of reporting.
Best for: AI governance teams, ML engineers, compliance leaders, data scientists, enterprise risk teams, and regulated industries using AI in decision-making.
Not ideal for: small experiments, low-risk internal AI tools, or teams that only need basic manual review without formal fairness measurement.
What’s Changed in Bias & Fairness Testing Suites
- Fairness testing now includes LLMs, not only predictive ML models.
- Teams are testing bias in prompts, responses, embeddings, and RAG outputs.
- Agentic AI requires fairness checks across tool actions and workflow decisions.
- Multimodal fairness testing is becoming more important for image, video, and voice AI.
- Evaluation suites now support red teaming for stereotyping, exclusion, and harmful assumptions.
- Fairness drift monitoring is becoming a production requirement.
- More buyers expect explainability linked directly to bias findings.
- Governance teams need audit-ready reports for internal and regulatory review.
- Privacy controls are critical when fairness testing uses sensitive attributes.
- Open-source fairness libraries are still valuable, but enterprises often need monitoring and reporting platforms.
- Fairness testing is increasingly combined with safety, compliance, and AI observability.
- Human-in-the-loop review is becoming essential for high-risk decisions.
Quick Buyer Checklist
- Does the tool support both ML models and LLM applications?
- Can it measure fairness across protected or sensitive groups?
- Does it support custom fairness metrics?
- Can it test bias in generated text, recommendations, and decisions?
- Does it provide explainability for why bias appears?
- Can it monitor fairness drift in production?
- Are audit logs and reports available?
- Does it integrate with MLOps, LLMOps, and data pipelines?
- Can it work with cloud, self-hosted, or hybrid environments?
- Does it support human review and escalation workflows?
- Are privacy and retention controls clearly defined?
- Can results be exported for governance or compliance teams?
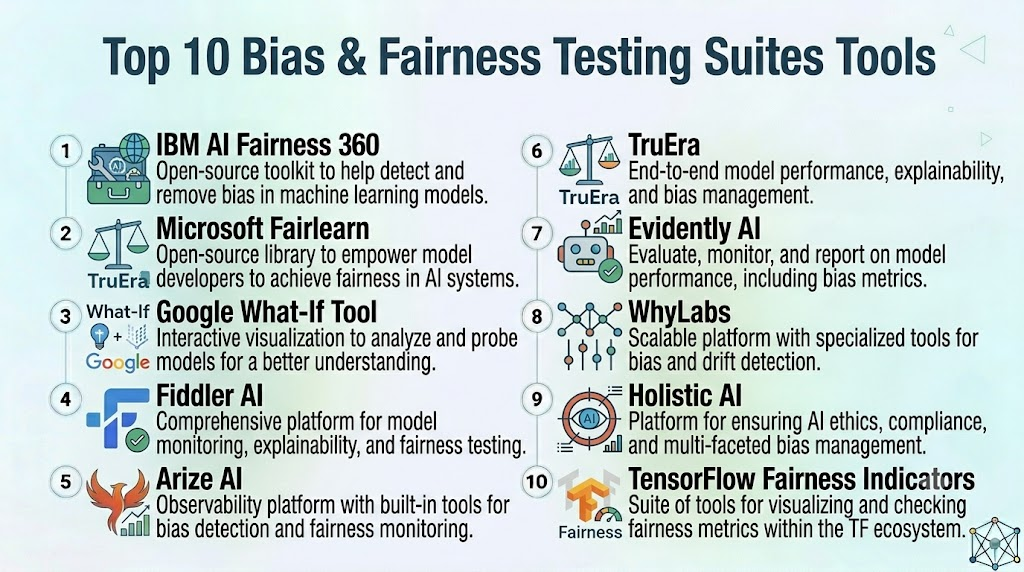
Top 10 Bias & Fairness Testing Suites Tools
1- IBM AI Fairness 360
One-line verdict: Best for teams needing open-source fairness metrics and bias mitigation algorithms.
Short description:
IBM AI Fairness 360 is an open-source toolkit for detecting and reducing bias in machine learning models. It is widely used by data scientists, researchers, and responsible AI teams that need transparent fairness testing workflows.
Standout Capabilities
- Bias detection across multiple fairness metrics
- Bias mitigation algorithms for pre-processing, in-processing, and post-processing
- Support for structured ML fairness testing
- Python and R ecosystem support
- Strong research and academic adoption
- Extensible framework for custom metrics
- Useful for governance prototypes and internal audits
AI-Specific Depth
- Model support: Traditional ML models, custom pipelines
- RAG / knowledge integration: N/A
- Evaluation: Strong fairness metrics and mitigation methods
- Guardrails: N/A
- Observability: Limited native production observability
Pros
- Strong open-source foundation
- Transparent and extensible
- Good for fairness research and model audits
Cons
- Requires technical expertise
- Limited production monitoring
- Not a complete enterprise governance platform
Security & Compliance
Not publicly stated. Security depends on how the toolkit is deployed and managed.
Deployment & Platforms
- Local
- Self-hosted
- Python and R environments
- Cloud deployment possible through custom setup
Integrations & Ecosystem
IBM AI Fairness 360 works well inside data science workflows where teams already use notebooks, Python pipelines, and ML experimentation tools.
- Python ecosystem
- R ecosystem
- Jupyter notebooks
- Custom ML pipelines
- Enterprise AI governance workflows through custom integration
Pricing Model
Open-source.
Best-Fit Scenarios
- Academic and research fairness testing
- Internal bias audits for ML models
- Custom responsible AI workflows
2- Microsoft Fairlearn
One-line verdict: Best for Python-based teams evaluating fairness in machine learning models.
Short description:
Fairlearn is an open-source toolkit that helps data scientists assess and improve fairness in ML models. It is useful for comparing model performance across groups and testing mitigation strategies.
Standout Capabilities
- Group fairness assessment
- Disparity visualization
- Fairness mitigation algorithms
- Python-native workflow
- Strong compatibility with scikit-learn
- Useful dashboards for model comparison
- Good fit for explainable fairness experiments
AI-Specific Depth
- Model support: Traditional ML models
- RAG / knowledge integration: N/A
- Evaluation: Strong fairness evaluation for structured ML
- Guardrails: N/A
- Observability: Limited native monitoring
Pros
- Easy for Python teams to adopt
- Strong educational and practical documentation
- Good for structured fairness evaluation
Cons
- Not built primarily for LLM fairness testing
- Requires sensitive attribute handling
- Limited enterprise reporting features
Security & Compliance
Not publicly stated. Security depends on deployment environment.
Deployment & Platforms
- Local
- Self-hosted
- Python environments
- Cloud notebooks and ML platforms through custom setup
Integrations & Ecosystem
Fairlearn fits naturally into existing Python ML workflows.
- Scikit-learn
- Jupyter
- Azure ML through custom workflows
- Python data science stack
- Custom model pipelines
Pricing Model
Open-source.
Best-Fit Scenarios
- ML fairness analysis
- Bias mitigation experiments
- Data science team workflows
3- Google What-If Tool
One-line verdict: Best for interactive model behavior analysis and fairness exploration.
Short description:
Google What-If Tool helps teams visually inspect model behavior, compare outcomes, and understand how predictions change across examples and groups. It is useful for exploratory fairness testing and model debugging.
Standout Capabilities
- Interactive model analysis
- Counterfactual testing
- Group-based performance comparison
- Visual fairness exploration
- Model behavior debugging
- Feature impact analysis
- Useful for education and experimentation
AI-Specific Depth
- Model support: Traditional ML models
- RAG / knowledge integration: N/A
- Evaluation: Fairness and performance exploration
- Guardrails: N/A
- Observability: Limited production monitoring
Pros
- Strong visual interface
- Helpful for understanding model behavior
- Good for exploratory fairness checks
Cons
- Not a full governance suite
- Limited LLM-native support
- Requires technical setup
Security & Compliance
Not publicly stated.
Deployment & Platforms
- Notebook-based workflows
- Cloud ML environments
- Local experimentation
Integrations & Ecosystem
Google What-If Tool is useful in experimentation workflows where teams want visual inspection of model behavior.
- TensorFlow ecosystem
- Jupyter notebooks
- Model analysis workflows
- Custom ML pipelines
Pricing Model
Open-source / free tooling, depending on deployment environment.
Best-Fit Scenarios
- Model debugging
- Fairness exploration
- Teaching and research use cases
4- Fiddler AI
One-line verdict: Best for enterprise teams monitoring fairness, explainability, and AI risk in production.
Short description:
Fiddler AI provides model observability, explainability, and responsible AI monitoring for ML and generative AI systems. It helps teams detect bias, track model behavior, and investigate performance issues.
Standout Capabilities
- Bias and fairness monitoring
- Explainability dashboards
- Model performance tracking
- Production drift detection
- LLM monitoring capabilities
- Root cause analysis
- Governance reporting support
AI-Specific Depth
- Model support: Multi-model
- RAG / knowledge integration: Varies / N/A
- Evaluation: Model quality, fairness, drift, and performance
- Guardrails: Limited compared with dedicated guardrail tools
- Observability: Strong production observability
Pros
- Strong enterprise monitoring
- Good explainability features
- Useful for regulated AI workflows
Cons
- More complex than open-source tools
- Enterprise pricing may not suit small teams
- Requires integration effort
Security & Compliance
SSO, RBAC, audit logs, and enterprise controls may be available depending on plan. Certifications are not publicly stated here.
Deployment & Platforms
- Cloud
- Enterprise deployment options may vary
- Web-based platform
Integrations & Ecosystem
Fiddler AI integrates with AI and ML workflows where teams need monitoring, explainability, and governance visibility.
- ML pipelines
- Cloud data platforms
- Model serving systems
- LLM application stacks
- Enterprise reporting workflows
Pricing Model
Enterprise SaaS pricing. Exact pricing is not publicly stated.
Best-Fit Scenarios
- Production model monitoring
- AI fairness governance
- Regulated enterprise AI systems
5- Arize AI
One-line verdict: Best for production AI teams needing observability and fairness-related model monitoring.
Short description:
Arize AI is an AI observability platform that helps teams monitor ML and LLM systems in production. It supports performance tracking, drift detection, evaluation workflows, and quality monitoring.
Standout Capabilities
- Production model monitoring
- LLM evaluation workflows
- Data and concept drift detection
- Prompt and response tracking
- Root cause analysis
- Segment-based performance analysis
- Alerting for model behavior changes
AI-Specific Depth
- Model support: Multi-model
- RAG / knowledge integration: Supported indirectly through observability workflows
- Evaluation: Strong LLM and ML evaluation support
- Guardrails: Not primarily a guardrail enforcement platform
- Observability: Strong
Pros
- Strong production observability
- Useful for LLM and ML systems
- Good for monitoring fairness drift by segment
Cons
- Not focused only on fairness testing
- Requires data and pipeline integration
- May be too advanced for small teams
Security & Compliance
Enterprise security features may vary by plan. Certifications are not publicly stated here.
Deployment & Platforms
- Cloud SaaS
- Web-based interface
- API-based integrations
Integrations & Ecosystem
Arize AI works well in modern AI engineering environments where teams need visibility across models and applications.
- ML pipelines
- LLM applications
- Observability stacks
- Cloud AI services
- Evaluation workflows
Pricing Model
Enterprise SaaS pricing. Exact pricing is not publicly stated.
Best-Fit Scenarios
- AI observability programs
- LLM evaluation pipelines
- Fairness drift monitoring in production
6- TruEra
One-line verdict: Best for teams focused on AI quality, explainability, and responsible AI diagnostics.
Short description:
TruEra focuses on AI quality management, explainability, testing, and monitoring for ML and generative AI systems. It helps teams identify model weaknesses, diagnose issues, and improve trustworthiness.
Standout Capabilities
- Model quality diagnostics
- Explainability tools
- Bias and fairness analysis
- Model comparison workflows
- LLM evaluation support
- Drift monitoring
- Debugging and root cause analysis
AI-Specific Depth
- Model support: Multi-model
- RAG / knowledge integration: Varies / N/A
- Evaluation: Strong model quality and fairness evaluation
- Guardrails: Limited compared with runtime safety tools
- Observability: Strong monitoring and diagnostics
Pros
- Strong model diagnostic capabilities
- Useful for fairness and explainability
- Enterprise-ready responsible AI workflows
Cons
- Requires integration effort
- May be complex for smaller teams
- Not a standalone policy enforcement tool
Security & Compliance
Not publicly stated.
Deployment & Platforms
- Cloud
- Enterprise deployment options may vary
- Web-based platform
Integrations & Ecosystem
TruEra fits into model development and monitoring workflows where teams need quality diagnostics and responsible AI analysis.
- ML pipelines
- Cloud AI platforms
- Data science workflows
- LLM evaluation systems
- Enterprise AI governance workflows
Pricing Model
Enterprise pricing. Exact pricing is not publicly stated.
Best-Fit Scenarios
- Model quality testing
- Responsible AI diagnostics
- Enterprise ML monitoring
7- Evidently AI
One-line verdict: Best for teams needing open-source model monitoring and fairness-adjacent evaluation workflows.
Short description:
Evidently AI helps teams monitor data drift, model performance, and data quality. While not only a fairness tool, it is useful for tracking segment-level model behavior and supporting responsible AI workflows.
Standout Capabilities
- Data drift detection
- Model performance monitoring
- Data quality checks
- Custom evaluation reports
- Open-source monitoring workflows
- LLM evaluation support
- Segment-based analysis
AI-Specific Depth
- Model support: ML and LLM workflows
- RAG / knowledge integration: Supported indirectly
- Evaluation: Strong monitoring and evaluation reports
- Guardrails: Limited
- Observability: Strong for open-source monitoring
Pros
- Open-source friendly
- Strong monitoring capabilities
- Flexible for custom workflows
Cons
- Not a dedicated bias mitigation suite
- Requires engineering setup
- Enterprise governance features vary
Security & Compliance
Not publicly stated.
Deployment & Platforms
- Self-hosted
- Cloud options may vary
- Python-based workflows
Integrations & Ecosystem
Evidently AI works well for ML teams that want flexible monitoring and reporting.
- Python ML stack
- Data pipelines
- Notebook workflows
- Model monitoring pipelines
- LLM evaluation workflows
Pricing Model
Open-source with enterprise options. Exact pricing is not publicly stated.
Best-Fit Scenarios
- Model drift monitoring
- Data quality evaluation
- Lightweight responsible AI reporting
8- WhyLabs
One-line verdict: Best for large-scale AI monitoring with data quality and drift visibility.
Short description:
WhyLabs provides AI observability for monitoring data quality, model performance, and production behavior. It can help teams detect fairness-related drift by monitoring segments and data distributions.
Standout Capabilities
- Data quality monitoring
- Drift detection
- Anomaly alerts
- Model performance tracking
- Privacy-aware telemetry
- Scalable production observability
- LLM monitoring support
AI-Specific Depth
- Model support: Multi-model
- RAG / knowledge integration: Varies / N/A
- Evaluation: Monitoring-focused evaluation
- Guardrails: Limited
- Observability: Strong
Pros
- Scales well for production systems
- Strong data quality monitoring
- Useful for early warning signals
Cons
- Not a dedicated fairness testing suite
- Requires careful metric setup
- Bias testing may need custom configuration
Security & Compliance
Not publicly stated.
Deployment & Platforms
- Cloud
- Enterprise deployment options may vary
- API-based monitoring
Integrations & Ecosystem
WhyLabs fits into production ML and AI monitoring environments.
- Data pipelines
- ML serving systems
- Cloud platforms
- Monitoring workflows
- LLM applications
Pricing Model
Enterprise SaaS pricing. Exact pricing is not publicly stated.
Best-Fit Scenarios
- Large-scale model monitoring
- Data drift tracking
- Production AI observability
9- Holistic AI
One-line verdict: Best for organizations needing AI governance, risk, and fairness assessment workflows.
Short description:
Holistic AI provides tools and services focused on AI governance, risk management, and responsible AI assessment. It is useful for organizations that need structured fairness and compliance workflows.
Standout Capabilities
- AI risk assessment workflows
- Bias and fairness evaluation
- Governance documentation support
- Audit preparation
- Responsible AI reporting
- Policy alignment support
- Enterprise risk management orientation
AI-Specific Depth
- Model support: Varies / N/A
- RAG / knowledge integration: Varies / N/A
- Evaluation: Fairness, risk, and governance assessment
- Guardrails: Governance-focused, not primarily runtime guardrails
- Observability: Varies / N/A
Pros
- Strong governance orientation
- Useful for compliance teams
- Good fit for structured AI risk reviews
Cons
- Less developer-first than open-source libraries
- Technical integration details may vary
- Pricing is not publicly stated
Security & Compliance
Not publicly stated.
Deployment & Platforms
- Cloud / service-based options may vary
- Enterprise workflows
Integrations & Ecosystem
Holistic AI is useful for organizations building a formal responsible AI program.
- Governance workflows
- Risk management processes
- Audit documentation
- Compliance teams
- AI assessment processes
Pricing Model
Not publicly stated.
Best-Fit Scenarios
- AI risk assessments
- Fairness governance programs
- Compliance-driven AI reviews
10- TensorFlow Fairness Indicators
One-line verdict: Best for TensorFlow teams needing fairness evaluation across model slices.
Short description:
TensorFlow Fairness Indicators helps teams evaluate model performance across different data slices. It is useful for identifying disparities in TensorFlow-based ML systems.
Standout Capabilities
- Slice-based fairness evaluation
- Model performance comparison by group
- TensorFlow ecosystem integration
- Visualization of fairness metrics
- Useful for model debugging
- Supports responsible ML workflows
- Works well in ML experimentation environments
AI-Specific Depth
- Model support: TensorFlow models
- RAG / knowledge integration: N/A
- Evaluation: Strong slice-based fairness evaluation
- Guardrails: N/A
- Observability: Limited outside custom workflows
Pros
- Strong fit for TensorFlow users
- Useful fairness visualization
- Good for structured ML workflows
Cons
- Limited outside TensorFlow ecosystem
- Not built for LLM fairness testing
- Requires technical setup
Security & Compliance
Not publicly stated.
Deployment & Platforms
- Local
- Self-hosted
- TensorFlow ecosystem
- Cloud deployment through custom setup
Integrations & Ecosystem
TensorFlow Fairness Indicators works best in TensorFlow-based model evaluation workflows.
- TensorFlow
- TensorFlow Model Analysis
- Notebook environments
- ML pipelines
- Custom fairness workflows
Pricing Model
Open-source.
Best-Fit Scenarios
- TensorFlow model audits
- Slice-based fairness testing
- ML experimentation workflows
Comparison Table
| Tool Name | Best For | Deployment | Model Flexibility | Strength | Watch-Out | Public Rating |
|---|---|---|---|---|---|---|
| IBM AI Fairness 360 | Open-source fairness testing | Self-hosted | ML models | Bias metrics and mitigation | Requires ML expertise | N/A |
| Microsoft Fairlearn | Python ML teams | Self-hosted | ML models | Fairness assessment | Limited LLM support | N/A |
| Google What-If Tool | Visual model debugging | Local / cloud | ML models | Interactive analysis | Not full governance | N/A |
| Fiddler AI | Enterprise monitoring | Cloud | Multi-model | Explainability and fairness monitoring | Enterprise complexity | N/A |
| Arize AI | AI observability | Cloud | Multi-model | Production monitoring | Not fairness-only | N/A |
| TruEra | AI quality diagnostics | Cloud | Multi-model | Model quality testing | Integration effort | N/A |
| Evidently AI | Open-source monitoring | Hybrid | ML and LLM workflows | Drift and data quality | Needs setup | N/A |
| WhyLabs | Scalable monitoring | Cloud | Multi-model | Data quality observability | Custom fairness setup | N/A |
| Holistic AI | AI governance teams | Varies | Varies / N/A | Risk and fairness assessment | Less developer-first | N/A |
| TensorFlow Fairness Indicators | TensorFlow teams | Self-hosted | TensorFlow models | Slice-based fairness | Ecosystem-specific | N/A |
Scoring & Evaluation
The scores below are comparative, not absolute. They reflect how each tool fits the Bias & Fairness Testing Suites category based on fairness testing depth, evaluation support, integrations, usability, observability, and enterprise readiness. A high score does not mean a tool is the best for every use case. Open-source tools may score lower on enterprise administration but remain excellent for technical teams. Enterprise tools may score higher on monitoring and governance but require more budget and implementation effort.
| Tool | Core | Reliability/Eval | Guardrails | Integrations | Ease | Perf/Cost | Security/Admin | Support | Weighted Total |
|---|---|---|---|---|---|---|---|---|---|
| IBM AI Fairness 360 | 9 | 8.5 | 6 | 7.5 | 7 | 8.5 | 6.5 | 8 | 7.8 |
| Microsoft Fairlearn | 8.5 | 8 | 6 | 8 | 8 | 8.5 | 6.5 | 8 | 7.8 |
| Google What-If Tool | 8 | 8 | 5.5 | 7.5 | 8 | 8 | 6 | 7.5 | 7.4 |
| Fiddler AI | 9 | 8.5 | 7.5 | 8.5 | 7.5 | 7.5 | 8.5 | 8 | 8.2 |
| Arize AI | 8.5 | 9 | 7 | 9 | 8 | 8 | 8 | 8 | 8.3 |
| TruEra | 8.5 | 9 | 7 | 8.5 | 7.5 | 7.5 | 8 | 8 | 8.1 |
| Evidently AI | 8 | 8.5 | 6.5 | 8 | 8.5 | 8.5 | 7 | 7.5 | 7.9 |
| WhyLabs | 8 | 8 | 6.5 | 8.5 | 8 | 8 | 8 | 8 | 7.9 |
| Holistic AI | 8 | 8 | 7 | 7.5 | 7.5 | 7 | 8 | 7.5 | 7.7 |
| TensorFlow Fairness Indicators | 8 | 8 | 5.5 | 7 | 7.5 | 8.5 | 6 | 7.5 | 7.3 |
Which Bias & Fairness Testing Suite Is Right for You?
Solo / Freelancer
Choose Fairlearn, AI Fairness 360, or TensorFlow Fairness Indicators if you need low-cost fairness testing inside Python or ML workflows. These tools are powerful but require technical skill.
SMB
SMBs should start with Evidently AI, Fairlearn, or AI Fairness 360. This combination provides practical monitoring, fairness metrics, and flexibility without large enterprise overhead.
Mid-Market
Mid-market teams should consider Arize AI, WhyLabs, or TruEra if they already have models in production and need monitoring, alerts, and evaluation workflows.
Enterprise
Enterprises should prioritize Fiddler AI, Arize AI, TruEra, or Holistic AI depending on whether the main need is observability, explainability, governance, or audit readiness.
Regulated industries
Finance, healthcare, insurance, education, and public-sector teams should prioritize tools with explainability, audit trails, segment-based fairness analysis, and governance reporting.
Budget vs premium
Open-source tools reduce cost but require engineering effort. Premium platforms provide dashboards, production monitoring, security controls, and governance workflows.
Build vs buy
Build when fairness logic is highly custom and your data science team is mature. Buy when you need production monitoring, audit reports, compliance workflows, and executive visibility.
Common Mistakes & How to Avoid Them
- Testing only overall accuracy and ignoring group-level outcomes
- Using fairness metrics without understanding business context
- Collecting sensitive attributes without privacy controls
- Assuming open-source fairness tools solve governance automatically
- Testing fairness only before deployment, not in production
- Ignoring intersectional groups and smaller segments
- Treating LLM bias as the same as traditional ML bias
- Forgetting to test multilingual and regional bias
- Not documenting fairness assumptions and limitations
- Overcorrecting models without measuring business impact
- Leaving fairness testing only to data scientists
- Skipping human review for high-risk decisions
- Not monitoring drift after data changes
- Choosing tools without checking integration fit
FAQs
1- What is a Bias & Fairness Testing Suite?
It is a tool or platform that helps teams detect whether AI models behave unfairly across groups, segments, or sensitive attributes. It can support fairness metrics, bias reports, mitigation methods, and production monitoring.
2- Why is fairness testing important for AI?
Fairness testing helps prevent discriminatory or harmful outcomes. It also improves trust, supports compliance, and helps teams understand how models behave beyond average performance.
3- Do fairness testing tools work for LLMs?
Some do, but not all. Traditional tools focus on structured ML models, while newer platforms and evaluation workflows support LLM outputs, prompt behavior, and generated content.
4- What fairness metrics should I use?
Common metrics include demographic parity, equal opportunity, disparate impact, error-rate differences, and calibration across groups. The right metric depends on the use case and risk level.
5- Can open-source tools be used in production?
Yes, but they usually require engineering work, monitoring setup, and governance processes. Open-source tools are excellent for testing but may not provide complete enterprise dashboards.
6- Do these tools remove bias automatically?
No. They help identify and reduce bias, but human judgment, domain expertise, better data, model changes, and policy decisions are still required.
7- How do fairness tools handle sensitive attributes?
Some tools require sensitive attributes for testing, but teams must handle this data carefully. Privacy controls, access restrictions, and clear governance policies are essential.
8- What is fairness drift?
Fairness drift happens when model behavior becomes less fair over time due to changes in users, data, business rules, or external conditions.
9- What is the difference between bias testing and explainability?
Bias testing measures unequal outcomes across groups. Explainability helps identify why the model produced those outcomes.
10- Are fairness tools only for regulated industries?
No. Any organization using AI in customer-facing, employee-facing, or decision-making workflows can benefit from fairness testing.
11- Can fairness testing increase model cost or latency?
Offline fairness testing usually has minimal runtime impact. Real-time monitoring or LLM evaluation can add cost, so buyers should plan carefully.
12- What is the best fairness testing tool?
There is no single best tool. Fairlearn and AI Fairness 360 are strong open-source options, while Arize AI, Fiddler AI, TruEra, and WhyLabs are better for production monitoring.
Conclusion
Bias & Fairness Testing Suites are becoming essential for organizations that want to deploy AI responsibly. Traditional ML fairness tools remain valuable for structured models, while newer observability and governance platforms help teams monitor fairness in production AI and LLM workflows. The best choice depends on your model type, risk level, technical maturity, compliance needs, and budget.