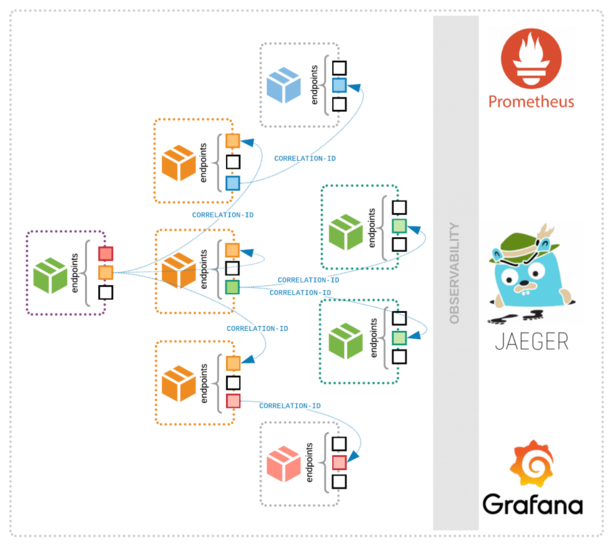
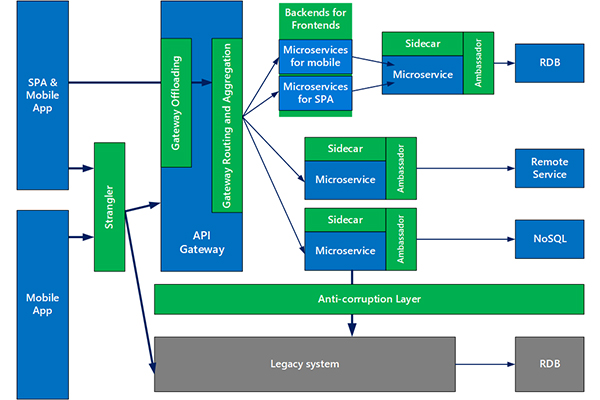
Source – opensource.com
Microservices have been a focus across the open source world for several years now. Although open source technologies such as Docker, Kubernetes, Prometheus, and Swarm make it easier than ever for organizations to adopt microservice architectures, getting your team on the same page about microservices remains a difficult challenge.
For a profession that stresses the importance of naming things well, we’ve done ourselves a disservice with microservices. The problem is that that there is nothing inherently “micro” about microservices. Some can be small, but size is relative and there’s no standard measurement unit across organizations. A “small” service at one company might be 1 million lines of code, but far fewer at another organization.
Some argue that microservices aren’t a new thing at all, rather a rebranding of service-oriented architecture (SOA), whereas others view microservices as an implementation of SOA, similar to how Scrum is an implementation of Agile. (For more on the ambiguity of microservice definitions, check out this upcoming book Microservices for Startups.)
How do you get your team on the same page about microservices when no precise definition exists? The most important thing when talking about microservices is to ensure that your team is grounded in a common starting point. Ambiguous definitions don’t help. It would be like trying to put Agile into practice without context for what you are trying to achieve or an understanding of precise methodologies like Scrum.
Finding common ground
Knowing the dangers of too eagerly hopping on the microservices bandwagon, a team I worked on tried not to stall on definitions and instead focused on defining the benefits we were trying to achieve with microservices adoption. Following are the three areas we focused on and lessons learned from each piece of our microservices implementation.
1. Ability to ship software faster
Our main application was a large codebase with several small teams of developers trying to build features for different purposes. This meant that every change had to try to satisfy all the different groups. For example, a database change that served only one group had to be reviewed and accepted by other groups that didn’t have as much context. This was tedious and slowed us down.
Having different groups of developers sharing the same codebase also meant that the code continually grew more complex in undeliberate ways. As the codebase grew larger, no one on the team could own it and make sure all the parts were organized and fit together optimally. This made deployment a scary ordeal. A one-line change to our application required the whole codebase to be deployed in order to push out the change. Because deploying our large application was high risk, our quality assurance process grew and, as a result, we deployed less.
With a microservices architecture, we hoped to be able to divide our code up so different teams of developers could fully own parts. This would enable teams to innovate much more quickly without tedious design, review, and deployment processes. We also hoped that having smaller codebases worked on by fewer developers would make our codebases easier to develop, test, and keep organized.
2. Flexibly with technology choices
Our main application was large, built with Ruby on Rails with a custom JavaScript framework and complex build processes. Several parts of our application hit major performance issues that were difficult to fix and brought down the rest of the application. We saw an opportunity to rewrite these parts of our application using a better approach. Our codebase was intertangled, which make rewriting feel extremely big and costly.
At the same time, one of our frontend teams wanted to pull away from our custom JavaScript framework and build product features with a newer framework like React. But mixing React into our existing application and complex frontend build process seemed expensive to configure.
As time went on, our teams grew frustrated with the feeling of being trapped in a codebase that was too big and expensive to fix or replace. By adopting microservices architecture, we hoped that keeping individual services smaller would mean that the cost to replace them with a better implementation would be much easier to manage. We also hoped to be able to pick the right tool for each job rather than being stuck with a one-size-fits-all approach. We’d have the flexibility to use multiple technologies across our different applications as we saw fit. If a team wanted to use something other than Ruby for better performance or switch from our custom JavaScript framework to React, they could do so.
3. Microservices are not a free lunch
In addition to outlining the benefits we hoped to achieve, we also made sure we were being realistic about the costs and challenges associated with building and managing microservices. Developing, hosting, and managing numerous services requires substantial overhead (and orchestrating a substantial number of different open source tools). A single, monolithic codebase running on a few processes can easily translate into a couple dozen processes across a handful of services, requiring load balancers, messaging layers, and clustering for resiliency. Managing all of this requires substantial skill and tooling.
Furthermore, microservices involve distributed systems that introduce a whole host of concerns such as network latency, fault tolerance, transactions, unreliable networks, and asynchronicity.
Setting your own microservices path
Once we defined the benefits and costs of microservices, we could talk about architecture without falling into counterproductive debates about who was doing microservices right or wrong. Instead of trying to find our way using others’ descriptions or examples of microservices, we instead focused on the core problems we were trying to solve.
- How would having more services help us ship software faster in the next six to 12 months?
- Were there strong technical advantages to using a specific tool for a portion of our system?
- Did we foresee wanting to replace one of the systems with a more appropriate one down the line?
- How did we want to structure our teams around services as we hired more people?
- Was the productivity gain from having more services worth the foreseeable costs?
In summary, here are five recommended steps for aligning your team before jumping into microservices:
- Learn about microservices while agreeing that there is no “right” definition.
- Define a common set of goals and objectives to avoid counterproductive debates.
- Discuss and memorialize your anticipated benefits and costs of adopting microservices.
- Avoid too eagerly hopping on the microservices bandwagon; be open to creative ideas and spirited debate about how best to architect your systems.
- Stay rooted in the benefits and costs your team identified.
Focus on making sure the team has a concretely defined set of common goals to work off. It’s more valuable to discuss and define what you’d like to achieve with microservices than it is to try and pin down what a microservice actually is.