Introduction
Synthetic Data Generation Platforms are AI-driven systems that create artificial but statistically realistic datasets used for training, testing, and validating machine learning models. Instead of relying solely on real-world data—which can be expensive, sensitive, or limited—these platforms generate high-quality synthetic images, text, tabular data, audio, and multimodal datasets.
synthetic data has become a foundational pillar of AI development. With increasing privacy regulations, data scarcity in edge cases, and demand for scalable training pipelines, synthetic data platforms help organizations accelerate AI development without compromising compliance or quality.
Real-world use cases include:
- Training autonomous vehicle perception systems with rare scenario data
- Generating synthetic medical records for healthcare AI models
- Creating fraud scenarios for financial risk modeling
- Producing balanced datasets for bias mitigation in LLM training
- Simulating customer behavior for recommendation systems
Key evaluation criteria for buyers:
- Data fidelity and statistical realism
- Support for multimodal data generation
- Privacy preservation and anonymization guarantees
- Integration with ML and MLOps pipelines
- Customizability of synthetic generation rules
- Scalability and performance
- Support for edge-case simulation
- API and automation capabilities
- Bias control and fairness modeling
- Observability and dataset versioning
Best for: AI/ML teams, data scientists, enterprise AI platforms, healthcare and finance organizations, and autonomous systems developers.
Not ideal for: Small-scale projects that rely only on simple static datasets.
What’s Changed in Synthetic Data Platforms
- Shift from rule-based generation to foundation model-driven synthetic generation
- Widespread use of diffusion models for image and video synthesis
- Integration of LLMs for text and structured data generation
- Strong emphasis on privacy-preserving synthetic data (differential privacy)
- Multimodal synthetic data generation (text + image + sensor fusion)
- Edge-case simulation for autonomous systems and robotics
- Real-time synthetic data streaming for training pipelines
- Automated bias detection and correction in synthetic datasets
- Tight integration with RAG and LLM training workflows
- Synthetic data used for reinforcement learning environments
- Dataset versioning and lineage tracking for compliance
- Enterprise-grade governance and auditability features
Quick Buyer Checklist
- Does it support multimodal synthetic data generation?
- Can it generate edge-case scenarios for your domain?
- Does it preserve privacy and remove sensitive patterns?
- Can it integrate with your ML training pipelines?
- Does it support API-based automation?
- Is dataset quality statistically validated?
- Does it support bias detection and mitigation?
- Can it scale to millions of synthetic samples?
- Does it support real-time or batch generation?
- Are outputs customizable via constraints or rules?
- Does it support versioning and reproducibility?
- Is it compliant with data privacy regulations?
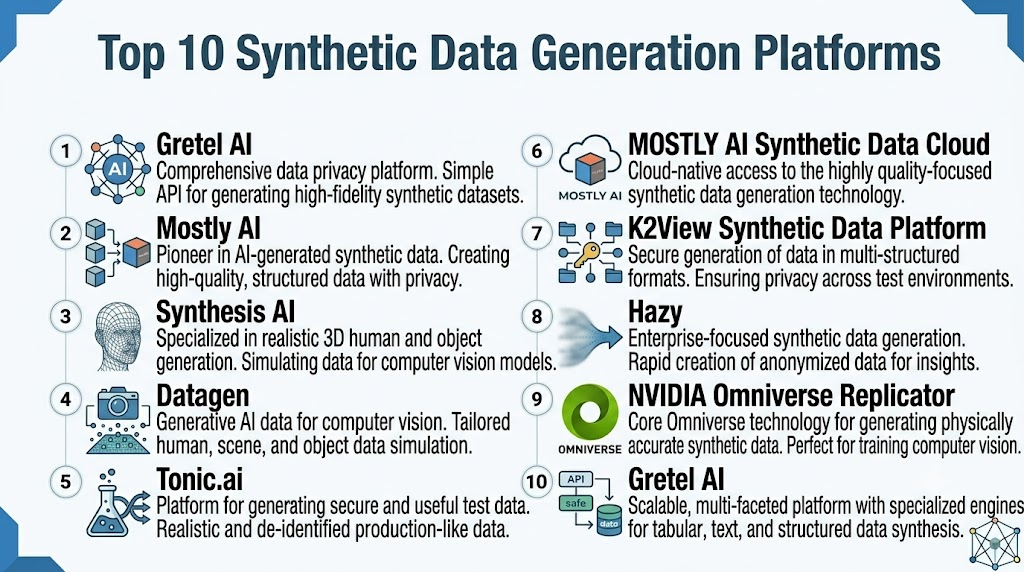
Top 10 Synthetic Data Generation Platforms
1 — Gretel AI
One-line verdict: Best enterprise-grade platform for privacy-safe synthetic data generation across structured and unstructured datasets.
Short description:
Gretel AI is a leading synthetic data platform that generates high-fidelity datasets while preserving privacy using advanced generative models.
Standout Capabilities
- Tabular, text, and time-series synthetic generation
- Differential privacy-based data protection
- Custom model training for synthetic outputs
- API-first data generation workflows
- Data anonymization and masking tools
- Schema-aware dataset synthesis
- Cloud-native scalability
AI-Specific Depth
- Model support: Generative models + LLM-based synthesis
- Data workflows: Structured + unstructured generation pipelines
- Privacy: Differential privacy + anonymization
- Bias control: Synthetic data balancing tools
- Observability: Dataset quality metrics and validation
Pros
- Strong privacy-first design
- High-quality structured data generation
- Easy API integration
Cons
- Premium pricing for enterprise usage
- Limited control for low-level model tuning
Security & Compliance
- Differential privacy support
- RBAC and access control
- Certifications: Not publicly stated
Deployment & Platforms
- Cloud-based SaaS platform
- API-first architecture
Integrations & Ecosystem
- ML pipelines
- Data warehouses
- MLOps platforms
- Cloud storage systems
Pricing Model
Usage-based enterprise pricing
Best-Fit Scenarios
- Financial modeling datasets
- Healthcare synthetic records
- Privacy-sensitive AI applications
2 — Mostly AI
One-line verdict: Best for enterprise-grade synthetic tabular data with strong compliance guarantees.
Short description:
Mostly AI specializes in generating highly realistic synthetic tabular data for regulated industries like banking, insurance, and healthcare.
Standout Capabilities
- High-fidelity tabular data synthesis
- Privacy-preserving generative models
- Data anonymization and masking
- API-based dataset generation
- Statistical similarity validation
- Data compliance reporting tools
- Scenario-based synthetic generation
AI-Specific Depth
- Model support: Tabular generative models
- Data workflows: Structured enterprise datasets
- Privacy: Strong anonymization guarantees
- Bias control: Statistical balancing tools
- Observability: Data similarity and drift metrics
Pros
- Excellent for structured enterprise data
- Strong compliance orientation
- High data realism
Cons
- Limited multimodal support
- Narrow focus on tabular data
Security & Compliance
- GDPR-ready design principles
- Enterprise access controls
- Certifications: Not publicly stated
Deployment & Platforms
- Cloud platform
- Enterprise on-prem options (varies)
Integrations & Ecosystem
- Data warehouses
- BI tools
- ML pipelines
- API integrations
Pricing Model
Enterprise subscription model
Best-Fit Scenarios
- Banking and financial datasets
- Insurance risk modeling
- Healthcare structured data generation
3 — Synthesis AI
One-line verdict: Best for photorealistic synthetic image and video generation for computer vision AI.
Short description:
Synthesis AI focuses on generating synthetic images, video, and 3D environments for training computer vision systems.
Standout Capabilities
- Photorealistic image generation
- 3D environment simulation
- Synthetic video generation
- Edge-case scenario creation
- Face and object variation synthesis
- Computer vision dataset augmentation
- Annotation-ready synthetic outputs
AI-Specific Depth
- Model support: Diffusion + generative vision models
- Data workflows: CV-focused synthetic pipelines
- Privacy: Fully synthetic non-identifiable data
- Bias control: Scene balancing tools
- Observability: Dataset diversity metrics
Pros
- Excellent for vision AI
- High realism in outputs
- Strong edge-case simulation
Cons
- Not suitable for tabular data
- Requires compute-heavy workflows
Security & Compliance
Not publicly stated
Deployment & Platforms
- Cloud-based platform
Integrations & Ecosystem
- Computer vision pipelines
- ML training systems
- Annotation tools
- Simulation engines
Pricing Model
Enterprise usage-based pricing
Best-Fit Scenarios
- Autonomous driving datasets
- Robotics vision systems
- Security surveillance AI
4 — Datagen
One-line verdict: Best for 3D synthetic human and environmental data for vision AI.
Short description:
Datagen generates high-quality synthetic datasets focused on human-centric computer vision applications.
Standout Capabilities
- 3D human modeling and pose generation
- Synthetic facial datasets
- Environmental scene generation
- Lighting and condition variation
- Edge-case simulation
- Annotation-ready synthetic outputs
- Dataset scaling tools
AI-Specific Depth
- Model support: 3D generative vision models
- Data workflows: Human-centric CV pipelines
- Privacy: Fully synthetic identity-free data
- Bias control: Demographic balancing tools
- Observability: Dataset variation metrics
Pros
- High-quality human simulation
- Strong realism in 3D data
- Excellent for CV use cases
Cons
- Limited non-vision use cases
- Enterprise pricing
Security & Compliance
Not publicly stated
Deployment & Platforms
- Cloud-based platform
Integrations & Ecosystem
- Computer vision frameworks
- Annotation platforms
- ML pipelines
Pricing Model
Enterprise subscription model
Best-Fit Scenarios
- Facial recognition AI
- AR/VR systems
- Human pose estimation models
5 — Tonic.ai
One-line verdict: Best for synthetic structured data generation for software testing and analytics.
Short description:
Tonic.ai generates safe synthetic datasets for developers and enterprises needing realistic but anonymized data.
Standout Capabilities
- Structured database synthesis
- Data masking and anonymization
- API-based data generation
- Test data provisioning
- Schema-aware generation
- Data cloning for dev environments
- Compliance-safe datasets
AI-Specific Depth
- Model support: Structured generative models
- Data workflows: Database replication pipelines
- Privacy: Strong anonymization and masking
- Bias control: Data distribution preservation
- Observability: Data validation reports
Pros
- Great for dev/test environments
- Strong compliance focus
- Easy integration with databases
Cons
- Limited multimodal capabilities
- Not suitable for CV or LLM training
Security & Compliance
- Strong enterprise security controls
- SOC2 alignment (where applicable, varies)
- RBAC and audit logs
Deployment & Platforms
- Cloud and on-prem options
Integrations & Ecosystem
- SQL databases
- Data warehouses
- CI/CD pipelines
- BI tools
Pricing Model
Enterprise licensing
Best-Fit Scenarios
- Software testing environments
- Dev/test data provisioning
- Compliance-safe analytics datasets
6 — MOSTLY AI Synthetic Data Cloud
One-line verdict: Best for scalable enterprise synthetic data pipelines with automation.
Short description:
An extension of Mostly AI offering scalable cloud-based synthetic data generation with automation and governance features.
Standout Capabilities
- Automated dataset synthesis
- Cloud-native scaling
- Data governance tools
- API-based workflows
- Statistical validation engine
- Scenario generation tools
- Enterprise compliance support
AI-Specific Depth
- Model support: Structured generative models
- Data workflows: Enterprise data pipelines
- Privacy: Strong anonymization
- Bias control: Statistical balancing
- Observability: Data quality dashboards
Pros
- Highly scalable
- Strong enterprise readiness
- Good governance features
Cons
- Limited multimodal capabilities
- Enterprise-focused pricing
Security & Compliance
Not publicly stated
Deployment & Platforms
- Cloud-based SaaS platform
Integrations & Ecosystem
- Data warehouses
- ML systems
- Enterprise analytics tools
Pricing Model
Enterprise subscription model
Best-Fit Scenarios
- Large-scale enterprise data generation
- Compliance-driven industries
- Financial modeling systems
7 — K2View Synthetic Data Platform
One-line verdict: Best for enterprise data masking and synthetic data generation at scale.
Short description:
K2View provides enterprise-grade synthetic data generation and data masking solutions for sensitive environments.
Standout Capabilities
- Real-time synthetic data generation
- Data masking and tokenization
- Enterprise data orchestration
- Schema-aware synthesis
- Multi-source data handling
- Compliance-driven workflows
- API automation
AI-Specific Depth
- Model support: Structured data generation models
- Data workflows: Enterprise pipelines
- Privacy: Strong masking + tokenization
- Bias control: Data consistency controls
- Observability: Audit-ready reporting
Pros
- Strong enterprise integration
- Real-time capabilities
- Good compliance features
Cons
- Complex setup
- Limited open-source ecosystem
Security & Compliance
Enterprise-grade controls with audit logs
Deployment & Platforms
- Cloud + on-prem deployment
Integrations & Ecosystem
- Data warehouses
- ETL systems
- Enterprise applications
Pricing Model
Enterprise licensing
Best-Fit Scenarios
- Telecom data systems
- Banking data protection
- Enterprise data masking workflows
8 — Hazy
One-line verdict: Best for privacy-first synthetic data generation in regulated industries.
Short description:
Hazy focuses on generating synthetic datasets that preserve privacy while maintaining statistical accuracy.
Standout Capabilities
- Privacy-preserving synthetic data
- Tabular dataset generation
- Regulatory compliance tools
- Data anonymization workflows
- API-based generation
- Dataset validation metrics
- Enterprise integration tools
AI-Specific Depth
- Model support: Tabular generative models
- Data workflows: Structured pipelines
- Privacy: Strong GDPR alignment
- Bias control: Distribution preservation
- Observability: Data validation reporting
Pros
- Strong compliance orientation
- High-quality structured outputs
- Easy integration
Cons
- Narrow focus (tabular data)
- Limited multimodal support
Security & Compliance
GDPR-focused privacy design
Deployment & Platforms
- Cloud-based platform
Integrations & Ecosystem
- Data warehouses
- BI systems
- ML pipelines
Pricing Model
Enterprise subscription
Best-Fit Scenarios
- Financial services data
- Healthcare analytics
- Regulatory reporting datasets
9 — NVIDIA Omniverse Replicator
One-line verdict: Best for physics-based synthetic data generation for robotics and vision AI.
Short description:
NVIDIA Omniverse Replicator generates physically accurate synthetic data for training AI systems in simulated environments.
Standout Capabilities
- Physics-based simulation environments
- 3D synthetic dataset generation
- Robotics training environments
- Camera and sensor simulation
- Edge-case scenario creation
- Real-time rendering pipelines
- Multimodal data generation
AI-Specific Depth
- Model support: Simulation + generative models
- Data workflows: Robotics + CV pipelines
- Privacy: Fully synthetic environments
- Bias control: Scenario balancing tools
- Observability: Simulation analytics
Pros
- Extremely realistic simulations
- Ideal for robotics AI
- Strong GPU acceleration
Cons
- High compute requirements
- Complex setup
Security & Compliance
Not publicly stated
Deployment & Platforms
- GPU-accelerated cloud + on-prem
Integrations & Ecosystem
- NVIDIA AI stack
- Robotics frameworks
- ML pipelines
- Simulation engines
Pricing Model
Enterprise licensing
Best-Fit Scenarios
- Robotics AI training
- Autonomous systems
- Industrial simulation environments
10 — Gretel AI
One-line verdict: Best general-purpose synthetic data platform with strong privacy controls.
Short description:
Gretel AI enables developers to generate synthetic datasets across structured and unstructured formats with strong privacy guarantees.
Standout Capabilities
- Multi-format synthetic generation
- Privacy-preserving models
- API-first architecture
- Data anonymization tools
- Schema-based synthesis
- Dataset validation engine
- Cloud scalability
AI-Specific Depth
- Model support: Generative AI models
- Data workflows: Multi-domain pipelines
- Privacy: Differential privacy support
- Bias control: Data balancing tools
- Observability: Data quality metrics
Pros
- Flexible and scalable
- Strong privacy features
- Developer-friendly APIs
Cons
- Enterprise pricing for scale
- Some advanced features require tuning
Security & Compliance
- Differential privacy support
- RBAC controls
- Certifications: Not publicly stated
Deployment & Platforms
- Cloud-based SaaS platform
Integrations & Ecosystem
- ML pipelines
- Data warehouses
- MLOps tools
- APIs and SDKs
Pricing Model
Usage-based enterprise pricing
Best-Fit Scenarios
- Privacy-sensitive AI systems
- Multi-domain synthetic data needs
- LLM and ML training pipelines
Comparison Table (Top 10)
| Tool Name | Best For | Deployment | Data Type | Strength | Watch-Out | Public Rating |
|---|---|---|---|---|---|---|
| Gretel AI | Privacy-safe synthesis | Cloud | Tabular/Text | Privacy-first | Cost at scale | N/A |
| Mostly AI | Enterprise tabular data | Cloud | Tabular | Compliance | Narrow scope | N/A |
| Synthesis AI | CV datasets | Cloud | Image/Video | Photorealism | Compute-heavy | N/A |
| Datagen | Human 3D data | Cloud | Image/3D | Human simulation | Limited domains | N/A |
| Tonic.ai | Dev/test data | Cloud/on-prem | Structured | Database masking | No multimodal | N/A |
| K2View | Enterprise masking | Hybrid | Structured | Real-time sync | Complexity | N/A |
| Hazy | Regulated industries | Cloud | Tabular | Privacy | Limited scope | N/A |
| NVIDIA Replicator | Robotics AI | Hybrid | Multimodal | Physics simulation | High compute | N/A |
| Gretel Cloud | Scalable pipelines | Cloud | Multi-format | Automation | Enterprise cost | N/A |
| Mostly AI Cloud | Enterprise scaling | Cloud | Tabular | Governance | Lock-in risk | N/A |
Scoring & Evaluation (Weighted Rubric)
| Tool | Core | Realism | Privacy | Multimodal | Ease | Performance | Security | Support | Weighted Total |
|---|---|---|---|---|---|---|---|---|---|
| Gretel AI | 9 | 9 | 10 | 8 | 8 | 8 | 9 | 8 | 8.7 |
| Mostly AI | 9 | 9 | 10 | 6 | 8 | 8 | 9 | 8 | 8.4 |
| Synthesis AI | 9 | 10 | 8 | 9 | 7 | 8 | 8 | 8 | 8.5 |
| Datagen | 9 | 9 | 8 | 9 | 7 | 8 | 8 | 8 | 8.3 |
| Tonic.ai | 8 | 8 | 10 | 6 | 9 | 8 | 9 | 8 | 8.2 |
| K2View | 8 | 8 | 9 | 6 | 7 | 8 | 9 | 8 | 7.9 |
| Hazy | 8 | 8 | 10 | 6 | 8 | 8 | 9 | 8 | 8.1 |
| NVIDIA Replicator | 10 | 10 | 8 | 10 | 6 | 10 | 8 | 8 | 8.6 |
| Gretel Cloud | 9 | 9 | 10 | 8 | 8 | 8 | 9 | 8 | 8.7 |
| Mostly AI Cloud | 9 | 9 | 10 | 6 | 8 | 8 | 9 | 8 | 8.4 |
Which Synthetic Data Tool Is Right for You?
Solo / Freelancer
Gretel AI (basic tier) and Tonic.ai are best for lightweight synthetic data needs.
SMB
Hazy, Datagen, and Synthesis AI provide balanced capabilities for growing AI teams.
Mid-Market
Mostly AI Cloud and Gretel AI Cloud offer scalable and structured pipelines.
Enterprise
NVIDIA Omniverse Replicator, Gretel AI, and K2View are best for large-scale, complex environments.
Regulated industries
Mostly AI, Hazy, and Tonic.ai offer strong privacy-first architectures.
Budget vs premium
- Budget: Tonic.ai
- Mid-range: Gretel AI, Hazy
- Premium: NVIDIA Replicator, Datagen
Build vs buy
- Build: Open pipelines + Gretel APIs
- Buy: Mostly AI, Datagen, Synthesis AI
Common Mistakes & How to Avoid Them
- Assuming synthetic data replaces real data completely
- Ignoring statistical validation of generated data
- Poor privacy configuration
- Not testing model performance on synthetic datasets
- Overfitting models to synthetic patterns
- Using single-source generation tools only
- Ignoring bias amplification in synthetic data
- No dataset version control
- Lack of multimodal support planning
- Not integrating with ML pipelines
- Over-reliance on default generation settings
- No real-world validation loop
- Ignoring edge-case simulation needs
- No governance or audit trail setup
FAQs
1. What is synthetic data?
Synthetic data is artificially generated data that mimics real-world data distributions without using actual sensitive data.
2. Why is synthetic data important?
It helps overcome privacy issues, data scarcity, and improves AI model training efficiency.
3. Is synthetic data as good as real data?
It depends on quality. High-fidelity synthetic data can significantly enhance model training but may not fully replace real-world data.
4. What types of synthetic data exist?
Tabular, text, image, video, audio, and multimodal synthetic datasets.
5. Is synthetic data safe for privacy?
Yes, when generated using privacy-preserving techniques like differential privacy.
6. Can synthetic data be used for LLM training?
Yes, it is widely used for fine-tuning and balancing LLM datasets.
7. What is multimodal synthetic data?
Data that combines multiple formats like text, images, and sensor data.
8. Do synthetic data tools require coding?
Some offer no-code interfaces, but most enterprise platforms use APIs.
9. What is the biggest risk of synthetic data?
Poor-quality synthetic data can introduce bias or degrade model performance.
10. Can synthetic data simulate edge cases?
Yes, it is one of its biggest advantages.
11. Is synthetic data cheaper than real data?
In most cases, yes, especially at large scale.
12. What is the future of synthetic data?
It is moving toward real-time, AI-generated, multimodal datasets integrated directly into training pipelines.
Conclusion
Synthetic Data Generation Platforms are becoming a core pillar of AI development, enabling scalable, privacy-safe, and cost-efficient model training across industries. As AI systems demand more data than ever before, synthetic data bridges the gap between data scarcity and model performance.
There is no single best tool. Gretel AI and Mostly AI lead in structured enterprise data, Synthesis AI and Datagen dominate computer vision, and NVIDIA Omniverse excels in simulation-based environments.