Source – techcrunch.com
We’ve already taken a look at neural networks and deep learning techniques in a previous post, so now it’s time to address another major component of deep learning: data — meaning the images, videos, emails, driving patterns, phrases, objects and so on that are used to train neural networks.
Surprisingly, despite our world being quite literally deluged by data — currently about 2.5 quintillion bytes a day, for those keeping tabs — a good chunk of it is not labeled or structured, meaning that for most current forms of supervised learning, it’s unusable. And deep learning in particular depends on a steady supply of the good, structured and labeled stuff.
In the second part of our “A Mathless Guide to Neural Networks,” we’ll take a look at why high-quality, labeled data is so important, where it comes from, how it’s used and what solutions our eager-to-learn machines can expect in the near-term future.
Supervised learning: I wanna hold your hand
In our post about neural networks, we explained how data is fed to machines through an elaborate sausage press that dissects, analyzes and even refines itself on the fly. This process is considered supervised learning in that the giant piles of data fed to the machines have been painstakingly labeled in advance. For example, to train a neural network to identify pictures of apples or oranges, it needs to be fed images that are labeled as such. The idea is that machines can be groomed to understand data by finding what all pictures labeled apple or orange, respectively, have in common, so they can eventually use those recognized patterns to more accurately predict what they are seeing in new images. The more labeled pictures they see, the bigger (and more diverse) the data set, the better they can refine the accuracy of their predictions; practice makes (almost) perfect.
This approach is useful in teaching machines about visual data, and how to identify anything from photographs and video to graphics and handwriting. The obvious upside is that it is now relatively commonplace for machines to be equal or even better than humans at say, image recognition for a number of applications. For instance, Facebook’s Deep Learning software is able to match two images of an unfamiliar person at the same level of accuracy as a human (better than 97 percent of the time), and Google, earlier this year, unveiled a neural network that can spot cancerous tumors in medical images more accurately than pathologists.
Unsupervised learning: Go west, young man
The companion to supervised learning, as you might guess, is called unsupervised learning. The idea is that you loosen the leash on your machine and let it dive into the data to discover and experience it on its own, look for patterns and connections and come to conclusions, without requiring the guidance of a chaperone.
This technique had long been frowned upon by a certain segment of artificial intelligence scientists, but, in 2012, Google demonstrated a deep learning network that was able to decipher cats, faces and other objects from a giant pile of unlabeled images. This technique is impressive and produces some extremely interesting and useful results, but, so far, unsupervised learning doesn’t match the accuracy and effectiveness of supervised training for many purposes — more on that in a bit.

Data, data, everywhere
It is in the chasm between these two techniques that we run into the larger issues that are proving to be confounding. It’s useful to liken these machines to human babies. We know that by simply setting our baby loose, without guidance, it’ll learn, but not necessarily what we want it to learn, nor in any predictable way. But since we also teach our baby by instructing it, then we need to expose it to large numbers of objects and concepts in an essentially infinite number of topics.
We need to teach our baby about directions, animals and plants, gravity and other physical properties, reading and language, food types and the elements, you know — the very stuff of existence. All of this can more or less be explained over time with a mix of show-and-tell and answering the endless questions that any curious young human asks.
It’s a tremendous undertaking, but one that most parents, as well as other people around the average child, take on each and every day on the fly. A neural network has the same needs, but its focus is usually more narrow and we don’t really socialize with it, so the labels need to be much more precise.
Currently there are a number of ways that AI researchers and scientists can get access to data to train their machines. The first way is to go out there and amass a giant stockpile of labeled data on their own. This happens to be the case for companies like Google, Amazon, Baidu, Apple, Microsoft and Facebook, all of which have businesses that, funnily enough, generate breathtaking amounts of data — much of it laboriously curated for free by customers.
It would be folly to try to list them all here, but think of the billions of labeled and tagged images uploaded to the cloud storage of all these companies’ databases. Then think about all the documents, the search queries — by voice, and text, and photos and optical character recognition— the location data and mapping, the ratings and likes and shares, the purchases, the delivery addresses, the phone numbers and contact info and address books and the social connections.
Legacy companies — and any company of huge scale — tend to have a unique advantage in machine learning in that they have copious amounts of specific types of data (which may or may not be valuable in the end, but often are).
Data the hard way
If you don’t happen to own a Fortune 100 company with collections of trillions of data points, then you’d better be good at sharing (or have deep pockets). Access to lots of extremely varied data is a key part of AI research. Fortunately, there already is a large number of free and publicly shared labeled data sets that cover a mind-boggling array of categories (this Wikipedia page hosts links to dozens and dozens).
Depending on your fancy, there are data sets showing everything from human facial expressions and sign language to the faces of public figures and skin pigmentation. You can find millions of images of crowds, forests and pets — all kinds of pets — or sift through boatloads of user and customer reviews. There also are data sets consisting of spam emails, tweets in multiple languages, blog posts and legal case reports.
New kinds of data are emerging from the myriad increasingly ubiquitous sensors in the world, such as medical sensors, motion sensors, smart device gyroscopes, heat sensors and more. And then there are all those pictures people take of their food, wine labels and ironic signage. In other words, there’s no shortage whatsoever of data in its purest form.
So what’s the problem?!?
Despite this apparent cornucopia of data, in practice, it turns out that many of these collections aren’t so broadly useful. Either they are too small of a collection, they are poorly or partially labeled or they just don’t meet your needs. For instance, if you’re hoping to teach a machine to recognize a Starbucks logo in images, you may only be able to find a training database of images that have been variously labeled “beverages” or “drinks” or “coffee” or “container” or “Joe.” Without the right labels, they just aren’t useful. And the average law firm or established corporation may have millions of millions of contracts or other paperwork in its databases, but that data isn’t usable as it’s likely in a simple unlabeled PDF format.
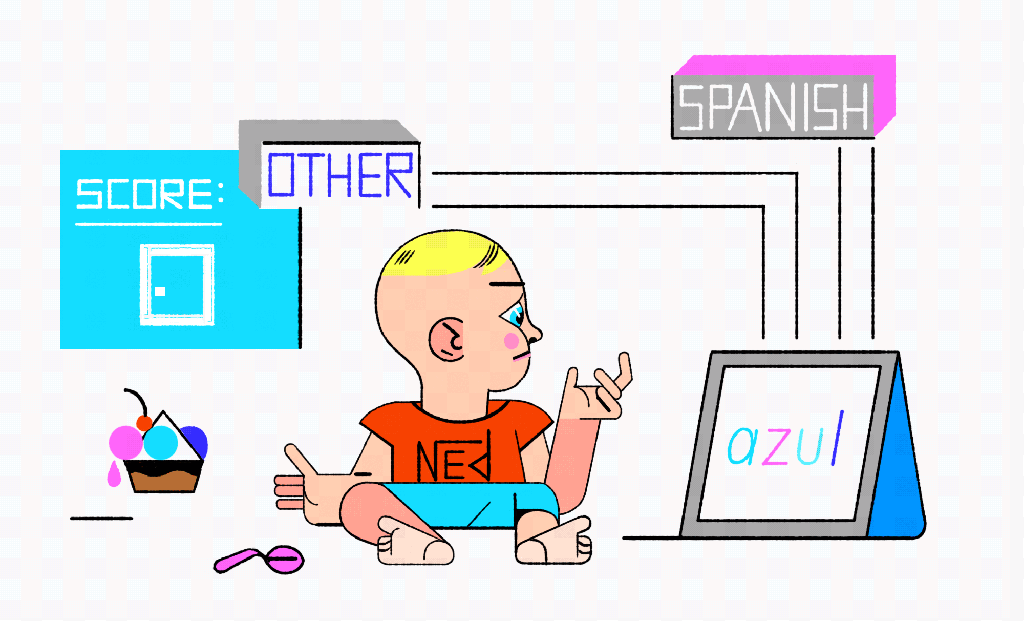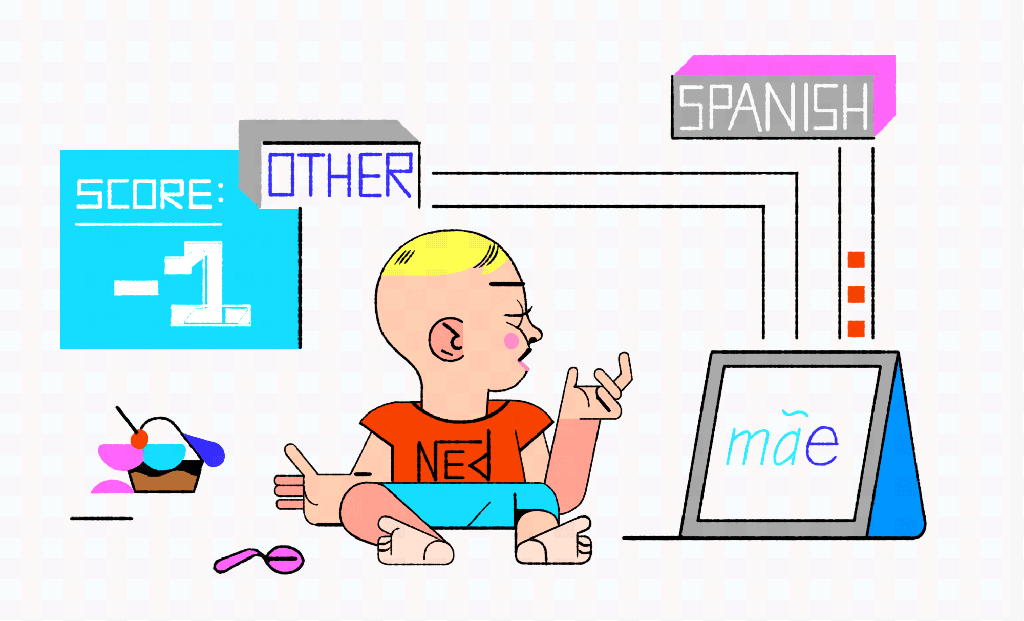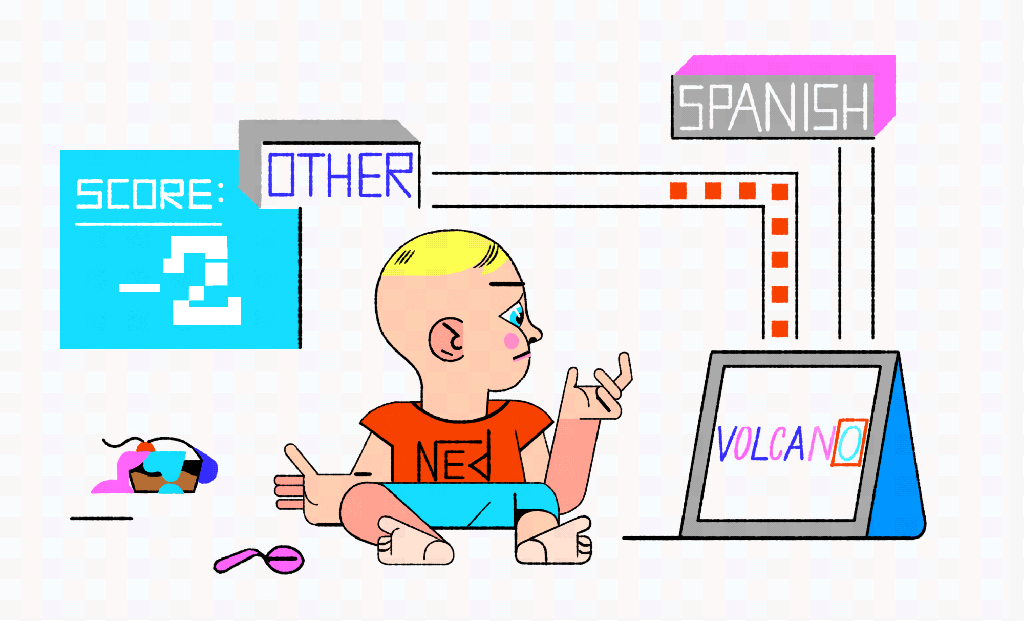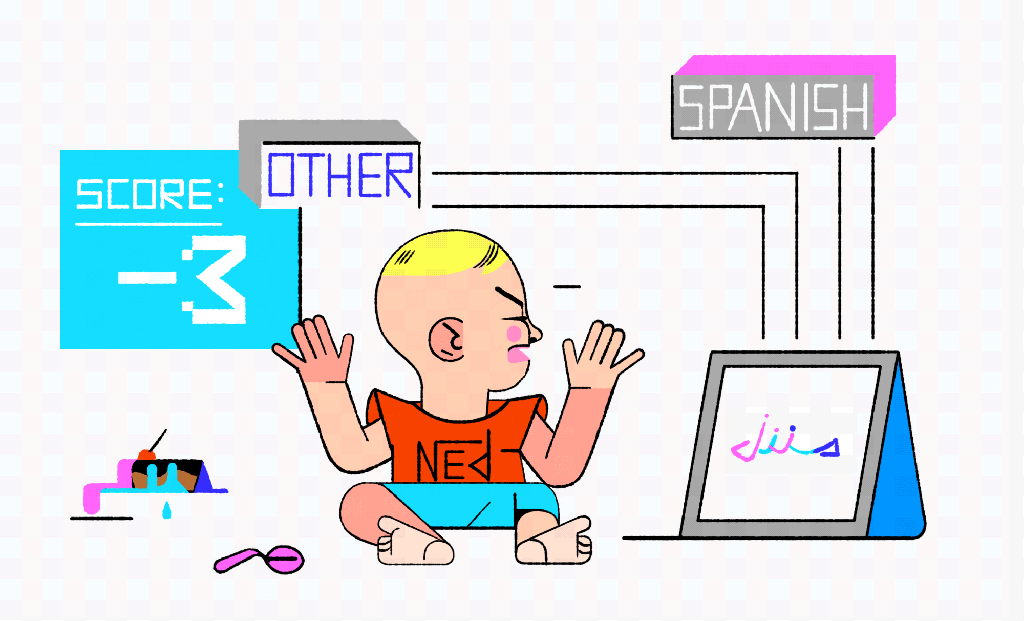
Another challenge in terms of optimal data is making sure that the training sets used are both large and diverse. Why? Let’s explore the idea of training data with a simple thought experiment. Imagine we give a little kid, we’ll call him Ned, the task of recognizing Spanish words on flashcards. When shown a flashcard, all Ned needs to do is say “Yes, this is Spanish” or “No, this is not Spanish.”
Having never seen nor spoken Spanish before, this kid Ned is given 10 random flashcards in order to learn what Spanish words do and do not look like. Five of the cards have the Spanish words: niño, rojo, comer, uno and enfermos, and the other five cards have words from other languages: cat, 猫, céu, yötaivas and नभ. Ned is told he can have a huge bowl of ice cream if he can pick out each of the Spanish words from a new set of flashcards. After an hour of studying, it’s time to test.
On the first test Ned is shown a Spanish word: azul. Because the character “a” only shows up in the non-Spanish pile, azul is not a Spanish word as far as Ned is concerned. The second card has the Portuguese word for mother: mãe. Ned immediately shouts, “Spanish!” Again, wrong answer, but his training cards include only one card with a tilde, and it happens to be in the Spanish pile. A third card has volcano on it. The boy notices that the word ends with an “o” and, remembering his training cards, he confidently says, “Spanish.” A fourth card showing “منزل” doesn’t look like anything from either pile and we can see tears building as the boy watches his ice cream melt. Is this a problem with his reasoning skills or his training data?
One issue: data set size. The boy has spent all his energy memorizing just 10 cards. In training a complex model, such as a deep neural network, the use of small data sets can lead to something called overfitting, which is a common pitfall in machine learning.
Essentially, overfitting is a consequence of having a large number of learnable parameters relative to training samples — parameters being those “neurons” that we were exhaustively adjusting via backpropagation in our previous article. The result can be a model that has memorized this training data as opposed to learning general concepts from the data.
Think of our apple-orange network. With a small amount of apple images as our training data and a large neural network, we risk causing the network to hone in on the specific details — the color red, brown stems a round shape — needed to accurately differentiate between just the training data. Those fine-grained details may do very well to describe the training apple pictures specifically, but prove to be inconsequential, or even incorrect, when trying to recognize new, unseen apples at test time.
Another issue, and an important principle, is data diversity. Ned would have been a lot better off if he had seen a non-Spanish word ending in “o” or a wider range of Spanish accent marks. Statistically speaking, the more unique data you accrue, the higher the probability that said data will span a more diverse range of features. In the case of the apple-orange network, we want it to generalize enough so that it recognizes all images of apples and oranges, regardless of whether they were present in the training set. Not all apples are red, after all, and if we train our network only on images of red apples (even if we have loads of them), we run the risk of the network not recognizing green apples at test time. Thus, if the types of data used during training are biased and not representative of data we expect at test time, expect trouble.
The issue of bias is beginning to crop up in a lot of AI. Neural networks and the data sets used to train them reflect any biases of the people or groups of people who put them together. Again, by only training our apple-orange network with images of red apples, we risk the network learning the bias that apples can only be red. What about green apples, yellow apples and candy apples? If you extrapolate to other applications, such as facial recognition, the impact that data bias can have becomes glaringly obvious. As the old saying goes: garbage in, garbage out.
Building a mousetrap that thinks for itself
Short of hiring people to label data — which is a thing, by the way, and it’s pricey — or all of the companies of the world suddenly agreeing to open up all their proprietary data and distribute it happily to scientists across the globe (we’d advise against holding your breath), then the answer to the shortage of good training data is not having to rely on it at all. That’s right, rather than working toward the goal of getting as much training data as possible, the future of deep learning may be to work toward unsupervised learning techniques. If we think about teaching babies and infants about the world, this makes sense; after all, while we do teach our children plenty, much of the most important learning we do as humans is experiential, ad hoc — unsupervised.


