Introduction
Humans can look at a photo of a cat and instantly recognize it. For computers, however, an image is just a massive grid of numbers representing color intensities. Teaching machines to bridge this gap and interpret visual information just like humans do is one of the most exciting achievements of modern computer science. The rapid growth of digital data has made visual automation essential across industries. From self-driving cars identifying pedestrians to medical systems detecting diseases in X-rays, intelligent vision technologies are reshaping how our world operates. Learning how these systems work is a critical milestone for any aspiring tech professional. To help you navigate this rapidly evolving field, AIUniverse.xyz provides a foundational look into the mechanisms driving smart visual analysis. This guide will walk you through the essential concepts, popular toolsets, and core methodologies that define the modern landscape of digital vision.
What Is AI for Image Recognition?
Definition
AI for Image Recognition is a subfield of computer vision that enables software to identify, categorize, and interpret specific objects, people, places, or actions within a digital image or video frame.
How Image Recognition Works
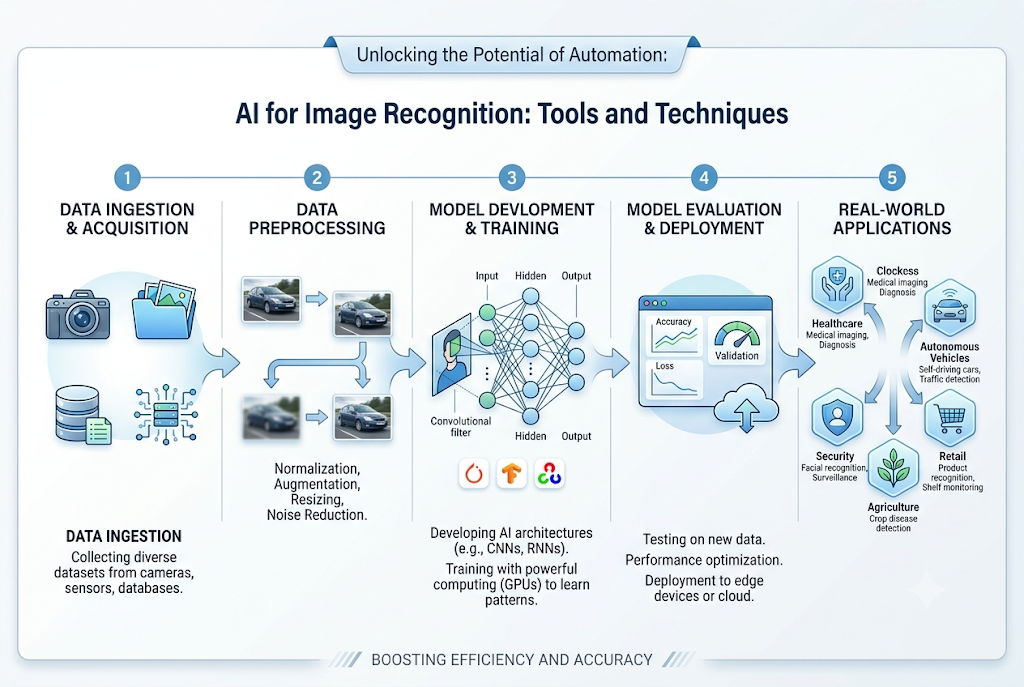
The process begins with data ingestion, where an image is converted into a numerical matrix. An artificial intelligence system analyzes these numbers to identify low-level pixel arrangements, such as edges, lines, and textures.
As the data passes deeper into the system, these basic shapes are combined to form complex structures, like eyes, wheels, or leaves. Finally, the system compares these extracted structures against its training data to output a label or classification with a calculated confidence score.
Difference Between Image Recognition and Computer Vision
While these terms are often used interchangeably, they represent different scopes of technology:
- Computer Vision is the overarching field that enables machines to see, process, and act upon visual data from the physical world. It includes video tracking, 3D reconstruction, and camera calibration.
- Image Recognition is a specific task within computer vision focused primarily on identifying and classifying visual elements within an image.
Why It Matters
Automating visual analysis allows industries to process data at a scale that is completely impossible for human workforces. It eliminates manual errors, speeds up operational workflows, and unlocks hidden patterns within massive visual archives.
Core Technologies Behind Image Recognition
Machine Learning
Machine learning forms the structural baseline of statistical image analysis. Instead of coding explicit rules to find a square or a circle, engineers feed algorithms thousands of labeled examples, allowing the math to determine the defining characteristics of an object.
Deep Learning
Deep learning scales this approach by utilizing multi-layered artificial neural networks. These deep architectures mimic the human brain’s interconnected pathways, automatically discovering hidden structures within complex pixel arrays without human intervention.
Convolutional Neural Networks (CNNs)
CNNs are the absolute workhorses of modern image recognition. They use specialized mathematical layers called filters to slide across an image, calculating localized pixel relationships to preserve the spatial orientation of shapes.
Transfer Learning
Building a powerful model from scratch requires millions of images and immense computing power. Transfer learning solves this by letting developers take a model pre-trained on a massive public dataset and fine-tune it for a specific, custom task with minimal data.
Image Processing
Before an image reaches an AI model, it must be cleaned and standardized. Image processing techniques like resizing, normalization, color conversion, and noise reduction ensure that the input data is optimized for algorithmic analysis.
Feature Extraction
Feature extraction is the automated step where a neural network discards irrelevant background pixels and retains only the critical descriptors—such as boundaries, contrasts, and unique shapes—needed to make an accurate prediction.
AI for Image Recognition: Tools and Techniques
Image Classification
This technique assigns a single label to an entire image based on its primary subject. For example, a classification model looks at a photo of a golden retriever and outputs the label “Dog.”
Object Detection
Object detection goes a step further by locating multiple items within a single frame. It draws bounding boxes around each item and labels them simultaneously, such as identifying three cars and two pedestrians on a city street.
Image Segmentation
Segmentation provides pixel-level precision by coloring every single pixel according to the exact boundaries of an object. This is widely used in medical imaging to outline the precise shape of an organ or a tumor.
Facial Recognition
This technique maps unique facial geometry, such as the distance between eyes and the contour of the jawline. It compares these spatial coordinates against a database to verify an individual’s identity, commonly used to unlock smartphones.
Optical Character Recognition (OCR)
OCR identifies printed or handwritten text characters within an image and converts them into editable, machine-readable digital text, making it easy to digitize paper invoices or street signs.
Pose Estimation
Pose estimation tracks the structural orientation of a human body by identifying key joints like elbows, knees, and shoulders. It is used extensively in fitness apps to analyze a user’s exercise form in real time.
Understanding Computer Vision Fundamentals
To build functional systems, you must first master how digital screens represent images. This means learning about color spaces like RGB and Grayscale, understanding pixel matrices, and recognizing how changes in brightness or contrast alter underlying digital data.
Choosing the Right AI Tools
Every practical project requires a specific operational balance. Developers must evaluate whether their application demands real-time speed on a low-powered mobile device or extreme accuracy running on high-end cloud servers before selecting their software stack.
Building Image Recognition Models
A standard development pipeline follows a systematic progression:
- Data Collection: Gathering a diverse set of images representing the target objects.
- Annotation: Drawing bounding boxes or adding labels to guide the learning process.
- Training: Passing the data through a neural network to optimize its internal weights.
- Validation: Testing the system on unseen images to verify its actual performance.
Evaluating Model Performance
Never trust a model based purely on its training success. True validation requires checking how well the system handles unseen variations, poor lighting, and unusual angles to ensure it can perform reliably in real-world environments.
Preparing for Real-World AI Projects
Transitioning from a prototype to a production environment involves optimizing your code for deployment. As emphasized by learning platforms like AIUniverse.xyz, engineering success relies on clean data management, efficient model architectures, and robust error-handling logic.
Popular Image Recognition Tools
OpenCV
- Purpose: An open-source library dedicated to real-time computer vision and fundamental image manipulation.
- Strengths: Lightweight, incredibly fast, and supports multiple programming languages like Python and C++.
- Ideal Use Case: Real-time camera streaming, image filtering, and classical pixel-based preprocessing transformations.
TensorFlow
- Purpose: An end-to-end open-source machine learning framework developed by Google.
- Strengths: Highly scalable, production-ready deployment ecosystems, and robust support for mobile devices via TensorFlow Lite.
- Ideal Use Case: Large-scale enterprise deep learning systems and cloud-based neural network model deployment.
PyTorch
- Purpose: A flexible, dynamic deep learning framework developed primarily by Meta’s AI Research lab.
- Strengths: Highly intuitive Python-first design, dynamic computation graphs, and an incredibly popular ecosystem among academic researchers.
- Ideal Use Case: Rapid prototyping, experimental research, and building custom neural network architectures.
YOLO (You Only Look Once)
- Purpose: A cutting-edge algorithmic framework designed specifically for ultra-fast, real-time object detection.
- Strengths: Processes an entire video frame in a single forward pass, delivering incredibly high inference speeds.
- Ideal Use Case: Live video surveillance, autonomous driving, and drone tracking applications.
Detectron2
- Purpose: Meta’s next-generation platform providing state-of-the-art detection and segmentation algorithms.
- Strengths: High modularity, highly extensible, and pre-packaged with advanced baseline models.
- Ideal Use Case: Industrial-grade object detection, instance segmentation, and complex visual research projects.
MediaPipe
- Purpose: Google’s open-source framework designed for building cross-platform multimodal applied AI pipelines.
- Strengths: Extremely low resource consumption, optimized for mobile phones and web browsers, with excellent pre-built solutions.
- Ideal Use Case: Real-time hand tracking, facial landmark detection, iris tracking, and mobile body-pose estimation.
Real-World Applications
Healthcare
Radiologists use intelligent vision tools to analyze MRI scans, X-rays, and CT scans. These systems highlight tiny anomalies or structural changes that might escape the human eye, accelerating diagnostic timelines for critical conditions.
Retail
Modern stores utilize visual intelligence to create cashierless shopping experiences. Overhead cameras track when a customer picks up an item from a shelf, adding it directly to a digital shopping cart and eliminating check-out lines entirely.
Manufacturing
Automated assembly lines use visual scanning to detect microscopic defects in products, such as hairline fractures on circuit boards or inconsistent packaging labels, keeping quality control standards incredibly high.
Agriculture
Drones equipped with advanced visual sensors fly over crop fields to evaluate plant health. The system analyzes leaf coloration patterns to pinpoint specific areas suffering from pest infestations or nutrient deficiencies.
Autonomous Vehicles
Self-driving vehicles rely on continuous visual streams to map out their surroundings. Object detection models categorize lane lines, traffic lights, road debris, and pedestrians in milliseconds to make safe driving decisions.
Security and Surveillance
Access control networks use facial analysis to secure physical facilities. Automated perimeters can flag unauthorized personnel or identify safety hazards, such as an employee entering a dangerous construction zone without a hard hat.
Social Media
Platforms automatically detect visual content to generate descriptive alt-text for visually impaired users. They also use visual tracking to align interactive filters precisely with a user’s facial movements.
Traditional Image Processing vs AI Image Recognition
| Feature | Traditional Image Processing | AI Image Recognition |
| Learning Capability | Rule-based; hardcoded by engineers | Learns implicitly from structured data |
| Accuracy | Limited for complex or dynamic tasks | High with quality training datasets |
| Adaptability | Low; requires rewriting code for changes | High; adapts via retraining with new data |
| Object Detection | Basic; relies heavily on edge contrast | Advanced; detects complex context and shapes |
| Scalability | Moderate; brittle under changing conditions | Excellent; scales seamlessly across domains |
Common Challenges
Poor Image Quality
Low resolution, motion blur, heavy shadows, and extreme weather conditions can degrade incoming pixel data, making it difficult for models to identify features.
- Recommendation: Apply preprocessing pipelines like histogram equalization, sharpening filters, and contrast adjustments before feeding data into the model.
Limited Training Data
Deep learning models are data-hungry. If you only provide a few dozen sample images, your network will struggle to generalize well to new environments.
- Recommendation: Use data augmentation techniques to artificially expand your dataset by rotating, flipping, zooming, and cropping existing images.
Bias in AI Models
If a facial analysis model is trained primarily on images of a specific demographic, its error rates will spike significantly when exposed to a broader, more diverse population.
- Recommendation: Audit your training datasets to ensure a balanced, well-rounded representation of all real-world edge cases and populations.
High Computational Requirements
Processing complex video feeds in real time using large neural networks requires expensive, power-heavy GPU infrastructure.
- Recommendation: Optimize your architectures using post-training quantization and model pruning to reduce their file sizes and computational footprints.
Privacy and Ethical Considerations
The widespread deployment of facial scanning technologies without explicit consent raises major regulatory and personal privacy concerns.
- Recommendation: Implement strict data-anonymization protocols, blur non-essential faces, and closely adhere to local data protection laws.
Best Practices
- Use High-Quality Datasets: Ensure your visual data is cleanly annotated, accurately labeled, and free from misleading artifact distortions.
- Continuously Validate Model Performance: Test your software regularly using dedicated validation sets that match real-world deployment conditions.
- Reduce Bias in Training Data: Maintain a balanced distribution of angles, backgrounds, lighting types, and subjects during data collection.
- Optimize Models for Deployment: Compress your models before sending them to edge devices to save local processing memory and battery life.
- Monitor Real-World Performance: Set up telemetry to track accuracy drift over time, updating the system periodically with fresh environmental data.
Key Performance Metrics
Accuracy
The simplest evaluation metric, tracking the percentage of total predictions that the model got correct across the entire test dataset.
Precision
Measures the proportion of positive identifications that were actually correct. High precision means the model rarely triggers false alarms.
Recall
Measures the proportion of actual positives that were correctly identified. High recall means the model rarely misses a true target object.
F1 Score
The harmonic mean of precision and recall. It provides a balanced performance metric, especially when dealing with unevenly distributed datasets.
Inference Time
The exact amount of time it takes for a trained model to process an input image and output a final prediction prediction matrix.
Model Efficiency
The overall computational footprint of the model, measuring memory usage, storage size, and processing draw during live execution.
Career Opportunities
Computer Vision Engineer
Develops, optimizes, and deploys specialized software architectures that process, analyze, and interpret real-world digital video and imagery.
AI Engineer
Integrates diverse machine learning workflows into broader software applications, managing cloud architectures and pipeline scaling.
Machine Learning Engineer
Designs the backend algorithmic foundations and training frameworks required to process massive structural neural networks cleanly.
Data Scientist
Analyzes visual datasets to discover underlying trends, curates training data structures, and evaluates statistical model performance.
AI Researcher
Pushes the boundaries of computer science by inventing new neural network structures, optimization math, and training approaches.
Robotics Vision Engineer
Combines spatial computer vision with physical hardware systems, enabling robotic arms or automated machinery to safely navigate environments.
Future of AI Image Recognition
Vision Transformers (ViTs)
Moving beyond standard convolutional layers, Vision Transformers utilize self-attention mechanisms to evaluate global context across an entire image simultaneously, leading to unprecedented accuracy gains.
Edge AI
Processing is shifting away from massive centralized cloud datacenters and moving directly onto local edge devices like smart cameras, drones, and microcontrollers, cutting down latency and saving bandwidth.
Multimodal AI
Modern AI architectures are blending visual processing with text and audio models. This enables systems to look at an image and engage in complex, conversational dialogue about what they are seeing.
Real-Time Computer Vision
As specialized hardware accelerators become cheaper, algorithms can process high-definition video frames at ultra-high frame rates without experiencing lag or stutter.
AI-Powered Robotics
The fusion of spatial awareness and physical mechanics allows industrial robots to dynamically adapt to unexpected changes on a factory floor, sorting irregular objects safely and autonomously.
Common Misconceptions
AI Understands Images Like Humans
- Reality: AI does not possess conscious awareness or situational understanding. It merely detects complex statistical pixel correlations based entirely on patterns it has seen before.
More Data Always Means Better Accuracy
- Reality: Low-quality, poorly labeled data will degrade your system regardless of volume. A smaller dataset containing flawless labels outperforms a massive dataset filled with messy annotations.
Image Recognition Is Only Used for Facial Recognition
- Reality: Facial scanning is just a highly publicized niche application. The underlying technology drives medical diagnostics, agricultural drone mapping, factory defect discovery, and logistics tracking.
AI Eliminates Human Oversight
- Reality: Smart vision systems act as extensions of human capability, not outright replacements. Human supervision remains essential for verifying edge cases, auditing errors, and guiding model retraining.
FAQ Section
- What is the best programming language for image recognition?
Python is widely considered the best programming language for image recognition due to its massive ecosystem of powerful libraries, easy-to-learn syntax, and strong community backing.
- Can I build an image recognition model without a powerful GPU?
Yes, you can use pre-trained models via transfer learning or leverage free cloud platforms like Google Colab to access high-end graphics cards directly inside your web browser.
- How many images do I need to train a custom model?
If you are using transfer learning, you can achieve impressive results with just a few hundred quality images per category, whereas building a model from scratch requires thousands.
- What is the main difference between object detection and image segmentation?
Object detection draws rectangular boxes around items to mark their locations, while image segmentation colors in every individual pixel belonging to the object for exact boundaries.
- Is OpenCV still relevant with the rise of deep learning?
Yes, OpenCV remains incredibly vital for essential tasks like resizing images, converting colors, managing live camera feeds, and running lightweight preprocessing pipelines.
- How does data augmentation improve model training?
Data augmentation modifies existing images by rotating, scaling, or flipping them, which exposes the neural network to new variations without requiring you to take more photos.
- What does an F1 score tell you about a model?
The F1 score combines precision and recall into a single metric, telling you how well your model balances finding all true targets while keeping false alarms to a minimum.
- Can image recognition systems work in total darkness?
Yes, when paired with infrared or thermal imaging cameras, image recognition models can be trained to analyze heat signatures and low-light pixel data effectively.
- What is model quantization?
Quantization is an optimization technique that reduces the numerical precision of a model’s weights, making the application significantly smaller and faster on mobile devices.
- Where can beginners find free datasets to practice computer vision?
Beginners can access thousands of free public datasets on open platforms like Kaggle, Roboflow, and Google Dataset Search to practice building their own vision applications.
Final Summary
AI for image recognition has evolved from a complex academic concept into an accessible, transformative technology powering modern global infrastructure. By moving past rigid rules and embracing deep learning structures like Convolutional Neural Networks, computers can now interpret complex visual environments with incredible speed and accuracy. Building effective vision applications requires a strong understanding of fundamental processing techniques, a familiarity with robust toolsets like PyTorch and YOLO, and a commitment to data quality. As emerging innovations like Vision Transformers and Edge AI continue to mature, the possibilities for intelligent automation will only expand.