Introduction
Artificial Intelligence has shifted from a futuristic concept discussed in research papers to the invisible engine powering our daily digital lives. Every time your smartphone unlocks using facial recognition, your email app auto-completes a sentence, or a streaming platform suggests a movie that perfectly matches your mood, an underlying intelligent architecture is at work. At the very heart of this technological shift are neural networks and deep learning. To help bridge the gap between academic theory and practical, real-world application, educational platforms like AIUniverse provide comprehensive learning paths designed to demystify these advanced concepts. Learning these fundamentals allows you to understand not just the “what” of artificial intelligence, but the “how.” By exploring the mechanisms behind intelligent systems, you can move from being a mere consumer of technology to an active participant in the ongoing AI transformation.
What Are Neural Networks and Deep Learning?
To understand how modern computing systems mimic human intelligence, it helps to look at the hierarchy of Artificial Intelligence. People often use AI, machine learning, and deep learning interchangeably, but they represent distinct, nested layers of technology:
- Artificial Intelligence (AI): The broadest category, encompassing any system, technique, or code that enables computers to mimic human behavior, logic, or decision-making.
- Machine Learning (ML): A specific subset of AI that focuses on giving computers the ability to learn from data over time without being explicitly programmed for every specific scenario.
- Deep Learning: A highly specialized subfield of machine learning that utilizes multi-layered artificial neural networks to learn deep, complex patterns from massive volumes of data.
+-------------------------------------------------------+
| Artificial Intelligence (AI) |
| +-------------------------------------------------+ |
| | Machine Learning (ML) | |
| | +-------------------------------------------+ | |
| | | Deep Learning | | |
| | | [ Artificial Neural Networks ] | | |
| | +-------------------------------------------+ | |
| +-------------------------------------------------+ |
+-------------------------------------------------------+
Inspiration from the Human Brain
The structural architecture of a deep learning model is conceptually inspired by the human biological brain. In your brain, a vast network of interconnected cells called biological neurons transmit electrical and chemical signals to process sensory information, formulate thoughts, and store long-term memories.
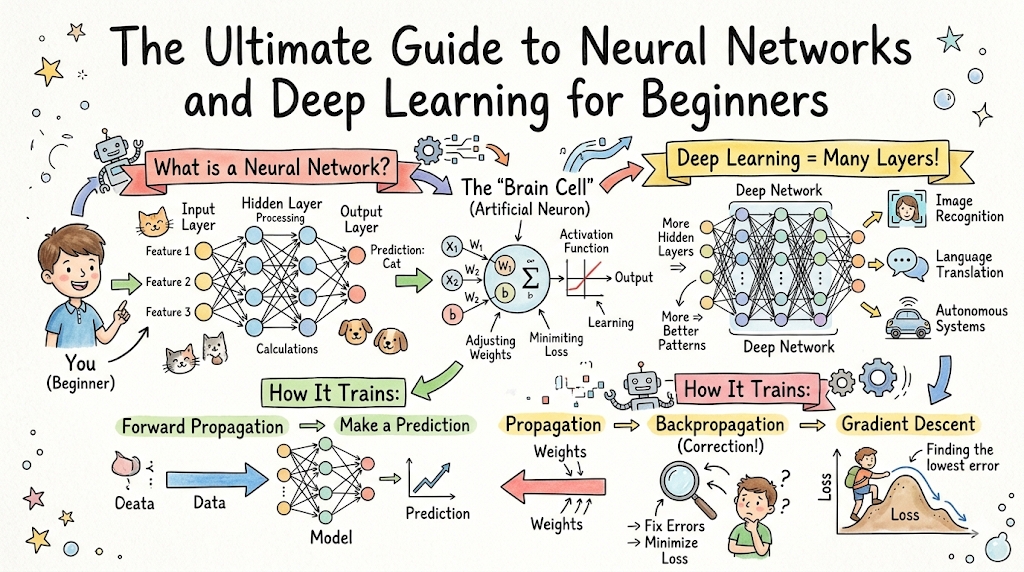
An artificial neural network attempts to replicate this biological structure in a simplified digital format. Instead of living organic cells, an artificial network is made up of software-based processing units called nodes, or artificial neurons. These nodes are organized in sequential layers and communicate with one another by passing mathematical values across digital connections.
How Artificial Neurons Work
An individual artificial neuron operates like a micro-decision-making unit. It receives multiple numerical inputs from a previous layer or raw data source, performs a specific mathematical calculation on those inputs, and passes the resulting output to the next neuron in line.
To visualize this simply, imagine you are trying to decide whether to go to an outdoor music concert this weekend. Your brain naturally weighs several factors, or inputs:
- Is the weather going to be clear?
- Is the ticket price reasonable?
- Are your close friends attending?
Each of these inputs holds a different level of importance to you. If you dislike rain, the weather forecast will heavily influence your final decision. If you have a strict budget, the ticket cost matters more. In an artificial neuron, these varying levels of importance are represented by numerical weights. The neuron multiplies each input by its corresponding weight, sums them all up, adds a slight adjustment called a bias, and runs the final number through a mathematical filter known as an activation function to determine whether to pass a signal forward.
The Evolution and Importance of Deep Learning
Artificial neural networks are not a brand-new discovery; the mathematical foundational concepts were established mid-way through the 20th century. However, early neural networks were strictly limited because they could only feature one or two processing layers. These shallow networks struggled with complex real-world tasks.
The modern rise of deep learning—where networks utilize dozens or even hundreds of hidden processing layers—became possible due to two main technological catalysts:
- Massive Data Availability: The explosion of the internet, mobile devices, enterprise databases, and digital sensors created the vast amounts of raw data that deep neural networks require to learn effectively.
- High-Performance Hardware: The adaptation of Graphics Processing Units (GPUs) and specialized AI chips allowed computers to perform millions of mathematical operations simultaneously, cutting down network training times from months to mere hours.
Traditional machine learning algorithms often plateau in performance once they receive a certain amount of data. Deep learning models, by contrast, continue to improve their accuracy and predictive power as more data is fed into them, making them highly effective for enterprise-scale automation.
Why Deep Learning Matters in Modern Technology
Deep learning has transitioned from research laboratories into the core infrastructures of modern enterprises. Its primary value lies in its unique capability to analyze unorganized, unstructured data—such as images, video feeds, raw audio recordings, and long-form text documents—without requiring human engineers to manually sort, tag, or label every single feature.
Computer Vision
Computer vision refers to the subfield of AI that enables machines to see, interpret, and understand visual data from the physical world. Deep neural networks process images by treating them as grids of numbers representing color pixels. By analyzing thousands of varied images, the network learns to detect basic edges, then shapes, and eventually complex objects.
In real-world scenarios, computer vision is what allows an automated quality control camera on a factory floor to detect microscopic structural cracks in manufactured components traveling down a high-speed assembly line. It is also the technology that powers automated sorting systems in logistics hubs and medical imaging software that helps specialists locate subtle anomalies in diagnostic scans.
Natural Language Processing (NLP)
Natural Language Processing allows computers to comprehend, interpret, translate, and generate human language in a natural, contextually accurate manner. Instead of merely looking for exact keyword matches, deep learning models analyze the relational context of words within sentences.
For businesses, advanced NLP models power intelligent enterprise virtual assistants and automated translation systems that help global operations communicate across language barriers. It also drives sentiment analysis platforms that scan thousands of customer product reviews or support tickets in real time, alerting company managers to specific customer service issues before they escalate.
Recommendation and Autonomous Systems
Modern digital platforms rely heavily on recommendation engines to drive user engagement and optimize sales pipelines. Deep learning architectures analyze millions of historical data points, including user click histories, viewing durations, purchase patterns, and demographic profiles, to surface highly relevant content or products tailored to an individual’s immediate context.
In more physical applications, autonomous systems leverage deep learning to safely navigate real-world environments without direct human intervention. Self-driving cars, warehouse delivery robots, and automated aerial drones continuously ingest multi-directional streams of live data from cameras, radar, and lidar sensors. Deep neural networks process this sensory information instantaneously to identify lane markings, navigate unexpected obstacles, read traffic signals, and make split-second driving decisions.
Predictive Analytics and Enterprise Intelligence
Enterprises across all sectors utilize deep learning for predictive analytics to forecast complex future trends based on vast stores of historical information. In the financial sector, deep neural networks analyze real-time market tickers, transaction histories, and global economic indicators to identify fraudulent credit card transactions or optimize institutional trading portfolios.
In supply chain management, predictive models look at weather patterns, seasonal demand fluctuations, and shipping route data to accurately calculate inventory requirements, minimizing overhead waste for retail and manufacturing organizations.
Core Concepts of Neural Networks
To build a solid understanding of deep learning, it helps to examine the core components and mathematical mechanisms that allow an artificial neural network to process information and learn from its mistakes.
Artificial Neurons
The fundamental building block of any neural network is the artificial neuron, often called a node. As a single processing unit, its job is to receive numeric inputs, modify those inputs based on internal parameters, and calculate a single numeric output value.
Inputs Weights
(x1) ------> [w1] ---\
\
(x2) ------> [w2] ----+--> [ Summation: Σ(x*w) + b ] ---> [ Activation Function ] ---> Output (y)
/
(x3) ------> [w3] ---/
Input, Hidden, and Output Layers
An artificial neural network is organized into structural vertical columns known as layers. Signals move through these layers sequentially:
- Input Layer: This is the entry point for the network. It receives the raw data from the outside world, such as the pixel values of a photograph or the text tokens of a document. It performs no complex mathematical calculations; it simply passes the raw values forward.
- Hidden Layers: These are the internal processing layers situated between the input layer and the final output layer. A network can have anywhere from one hidden layer to hundreds of them—which is why the technology is termed deep learning. These layers extract increasingly abstract patterns from the data.
- Output Layer: The final layer of the network, which delivers the ultimate prediction or classification result, such as identifying an image as a “car” or predicting a future stock price.
Weights and Biases
Weights and biases are the internal knobs and dials of a neural network. They represent the adjustable values that the network modifies over time during its training process to improve its overall accuracy.
- Weights: Every single connection between two artificial neurons has an assigned weight. A weight is a multiplier that determines how much influence a specific input value will have on the next neuron’s output. A high weight means that input is highly critical to the final decision; a weight close to zero means the input is largely ignored.
- Biases: A bias is an additional constant value added to the weighted sum of inputs before it enters the activation function. It acts as an offset, allowing the neuron to adjust its activation threshold up or down regardless of the raw incoming input values.
Activation Functions
Once a neuron calculates the sum of its inputs multiplied by their respective weights and adds the bias, it passes that total value through an activation function. The activation function acts as a mathematical filter that decides whether the neuron should fire a strong signal, a weak signal, or no signal at all to the next layer.
Without activation functions, a neural network would just be performing basic linear math, which prevents it from learning complex shapes, curves, and patterns. Common activation functions include:
- ReLU (Rectified Linear Unit): The most widely used activation function in hidden layers. If the incoming value is negative, it outputs zero; if it is positive, it outputs the exact same value. This simple mechanism makes the network incredibly fast to train.
- Sigmoid: Converts any incoming numeric value into a tight decimal range between 0 and 1. This is highly useful in the final output layer when a network needs to predict a probability.
- Softmax: Used specifically in the final output layer for multi-class classification problems, ensuring that the combined sum of all output probabilities equals exactly 100%.
Training Data and Supervised Learning
For a neural network to learn, it must be provided with data. In supervised learning—the most common approach for beginners—the network is trained using a dataset that contains both the raw input data and the correct corresponding answers, known as ground truth labels.
For instance, if you are training a network to recognize handwritten numbers, the training data will consist of thousands of pixel images of handwritten digits, with each image explicitly labeled with the actual number (0 through 9) it represents.
Backpropagation and Loss Functions
A neural network does not start out knowing how to make accurate predictions. When training begins, its weights and biases are initialized to completely random numbers, meaning its initial predictions are essentially random guesses. The learning process relies on two core steps:
- Forward Propagation: The network takes an input, passes it forward through its layers, and generates an initial prediction.
- The Loss Function: A mathematical formula that calculates the exact difference between the network’s prediction and the correct ground truth label. A high loss value means the network made a poor guess; a low loss value means it was highly accurate.
Once the loss is calculated, the network performs Backpropagation. The network calculates how much each individual weight and bias contributed to the overall error by tracing the signal backward from the output layer to the input layer.
Model Optimization
After backpropagation determines who was responsible for the error, an optimization algorithm steps in to adjust the weights and biases. The most fundamental optimization algorithm is called Gradient Descent.
Imagine you are standing at the top of a foggy mountain range and need to find the absolute lowest point in the valley below without being able to see the path. You would naturally feel the slope of the ground beneath your feet and take a small step in the downward direction. Gradient descent does exactly this with math. It calculates the slope (gradient) of the loss function and makes minor, calculated updates to the network’s internal weights to steadily move toward the lowest possible error rate.
Deep Learning Architecture and Workflow
Building a dependable, enterprise-grade deep learning system requires a structured, end-to-end operational workflow that extends far beyond writing model code.
+------------+ +---------------+ +----------------+ +--------------------+
| 1. Data | --> | 2. Data | --> | 3. Model | --> | 4. Optimization |
| Collection | | Preprocessing | | Architecture | | & Training |
+------------+ +---------------+ +----------------+ +--------------------+
|
+------------+ +---------------+ +----------------+ |
| 8. Contin. | <-- | 7. Live | <-- | 5. Evaluation | <-------------/
| Iteration | | Inference | | & Validation |
+------------+ +---------------+ +----------------+
1. Data Collection
The foundation of any successful deep learning implementation is the collection of a high-quality, diverse, and sufficiently large dataset. Depending on the targeted business outcome, data collection might involve aggregating customer purchase logs from enterprise databases, harvesting public text datasets, gathering sensor readouts from physical equipment, or licensing structured image repositories.
2. Data Preprocessing
Raw real-world data is notoriously messy. It frequently contains missing entries, duplicate lines, or formatting inconsistencies. During the preprocessing phase, data science teams clean the data, normalize numeric ranges so that giant numbers do not overwhelm small numbers, and convert text or categorical labels into clean mathematical matrices that a neural network can ingest.
3. Selecting Model Architecture
Architects evaluate the business problem to select the ideal structure for the neural network. Different architectures excel at different tasks:
- Convolutional Neural Networks (CNNs): Designed specifically for spatial data like images and video streams.
- Recurrent Neural Networks (RNNs) and Transformers: Tailored for sequential data like spoken language, written text, or time-series financial data.
4. Model Training and Optimization
The preprocessed data is systematically fed into the selected neural network architecture in small batches. The network performs forward propagation, evaluates its accuracy against the loss function, runs backpropagation to trace errors, and utilizes an optimizer to update its internal weights. This cycle repeats across many training loops, known as epochs.
5. Evaluation and Validation
To guarantee that a model has truly learned underlying patterns rather than just memorized the training examples, engineers evaluate its performance using a separate validation dataset that the network has never seen before. This step helps catch overfitting—a common issue where a model performs flawlessly on training data but fails to make accurate predictions on new data.
6. Production Deployment and Live Inference
Once a model achieves acceptable accuracy metrics on the validation data, it is moved out of the development environment and deployed onto live production servers. Here, it enters the inference phase, where it receives fresh, un-labeled data from real-world users and provides rapid predictions or automated decisions.
7. Continuous Monitoring and Iteration
A deployed model’s job is never truly done. Real-world conditions evolve over time, leading to a phenomenon called model drift, where a model’s accuracy slowly declines as real-world trends shift away from what was captured in the original training data. MLOps teams continuously track real-time performance metrics and periodically retrain the model with fresh data to ensure long-term stability and accuracy.
Neural Network Training Lifecycle
The end-to-end lifecycle of a neural network involves distinct operational stages, each requiring specific technologies and producing definitive technical outcomes.
| Stage | Purpose | Common Technologies Used | Real-World Outcome |
| Data Collection | Gather sufficient raw information to train the deep learning model. | SQL, Apache Kafka, AWS S3, Web Scrapers | A large repository of raw files, logs, images, or documents. |
| Data Preparation | Clean, format, and normalize raw data into a structured mathematical input format. | Pandas, NumPy, OpenCV, Scikit-learn | Structured, clean datasets split into training, validation, and testing sets. |
| Model Design | Define the structural layers, neurons, activation functions, and overall network architecture. | PyTorch, TensorFlow, Keras | A coded, un-trained neural network framework ready to accept input values. |
| Training | Run data through the network repeatedly to adjust weights and biases using optimization math. | NVIDIA GPUs, CUDA, Adam Optimizer | A trained model file containing highly optimized internal weights and parameters. |
| Validation | Monitor performance during training to tune hyperparameters and prevent overfitting. | TensorBoard, Weights & Biases | Fine-tuned model configurations with optimized accuracy balances. |
| Testing | Perform a final independent check on a separate dataset to verify true real-world readiness. | Scikit-learn Metrics, PyTest | Clear, definitive accuracy, precision, and recall performance reports. |
| Deployment | Integrate the finalized model into production servers so applications can access its predictions. | Docker, Kubernetes, FastAPI, Triton Inference Server | Live API endpoints that accept user data and return real-time predictions. |
| Continuous Optimization | Track real-world accuracy over time and retrain the model with new data as trends evolve. | MLflow, Kubeflow, Prometheus, Grafana | An evergreen, stable AI production pipeline that adapts to real-world shifts. |
Popular Deep Learning Frameworks and Tools
The rapid expansion of deep learning is largely supported by an open-source ecosystem of highly specialized frameworks, libraries, and cloud infrastructure platforms.
Machine Learning and Deep Learning Libraries
- PyTorch: Developed primarily by Meta’s AI research division, PyTorch has become the leading favorite tool among researchers and developers alike. Its dynamic computation graphs allow you to modify how a model behaves on the fly, making it highly intuitive, clear to debug, and developer-friendly.
- TensorFlow and Keras: Created by Google, TensorFlow is an enterprise-scale powerhouse built for heavy production deployments. Keras acts as a high-level user interface that sits directly on top of TensorFlow, allowing beginners to construct complex neural network architectures using just a few simple, clean lines of code.
Cloud AI Platforms and Data Tools
- Cloud Infrastructure (AWS SageMaker, Google Cloud Vertex AI, Azure ML): These cloud services allow developers to rent high-powered GPU instances on demand, removing the need to buy expensive computer hardware when training massive deep learning models.
- Data Processing and Tracking (Pandas, MLflow, TensorBoard): Essential support utilities used to manipulate unstructured datasets, track training progress metrics in real time, and catalog different versions of models as they undergo iterative development.
Frameworks Comparison
| Tool Name | Core Purpose | Learning Difficulty | Enterprise Adoption | Primary Advantage |
| PyTorch | Deep Learning Development | Medium | Exceptionally High | Intuitive Python integration and flexible debugging. |
| TensorFlow | Production AI Scale Deployment | High | High | Highly robust for large-scale enterprise pipelines. |
| Keras | Rapid Prototyping | Low | High (via TensorFlow) | Clean, human-readable code that is highly beginner-friendly. |
| Vertex AI | Managed Cloud Machine Learning | Medium | High | Seamlessly handles cloud infrastructure management. |
| MLflow | Machine Learning Lifecycle Tracking | Low | Medium | Simplifies model versioning and tracking experiment metrics. |
Real-World Applications of Deep Learning
Deep learning is actively driving major innovations across almost every modern global and local industry vertical.
Healthcare AI
In medicine, deep neural networks function as an extra set of expert eyes for diagnostics. Convolutional Neural Networks analyze high-resolution medical images—such as X-rays, MRIs, and CT scans—to assist radiologists in detecting subtle anomalies, tumors, or early-stage cardiovascular conditions with high precision. Furthermore, deep learning models analyze molecular data structures to accelerate pharmaceutical drug discovery pipelines, cutting down the years required to discover life-saving medications.
Autonomous Mobility
The automotive sector leverages deep learning to turn autonomous driving into a reality. Self-driving vehicles process simultaneous data streams from cameras and sensor arrays to map out their surrounding environment in real time. Deep learning algorithms identify nearby cars, track pedestrian movements, read traffic indicators, and predict potential hazards to calculate safe driving trajectories.
Customer Operations and NLP
Enterprise customer service has shifted from rigid, menu-driven automated phone trees to intelligent conversational AI. Modern AI-driven virtual assistants leverage advanced natural language processing to comprehend the true underlying intent behind customer queries, resolve complex account issues independently, and draft context-specific responses that mimic natural human conversation.
Financial Fraud Detection
Financial institutions process millions of electronic transactions every hour. Deep learning models run continuously in the background, analyzing transactions instantly to identify micro-patterns—such as unusual purchasing speeds, sudden geographic shifts, or anomalous transaction sizes—that deviate from an individual’s normal baseline behavioral profile. This allows banks to flag and freeze fraudulent credit card usage within milliseconds, protecting global consumer assets.
Benefits of Neural Networks and Deep Learning
Implementing deep learning architectures provides modern enterprises with several distinct operational advantages:
- Automated Feature Extraction: Unlike traditional machine learning, which requires human engineers to manually clean, tag, and isolate key features from data, deep learning models automatically discover relevant characteristics on their own simply by analyzing the raw input.
- Superior Scalability with Large Datasets: Traditional algorithms reach an accuracy ceiling where adding more data does not improve results. Deep neural networks, however, scale efficiently, growing more precise as they ingest larger volumes of data.
- Unstructured Data Processing: Deep learning allows software systems to extract valuable business insights from unstructured files like videos, voice calls, emails, and PDFs, which make up the vast majority of modern enterprise data.
- Real-Time Automated Decisioning: Once fully trained, deep learning models perform inference within milliseconds, enabling automated systems to make split-second decisions in high-velocity environments like electronic stock exchanges or robotic assembly lines.
Challenges and Limitations
While deep learning is incredibly powerful, it is not a magic solution for every problem. Developing these systems comes with a clear set of challenges that engineering teams must navigate:
- Massive Data Requirements: Deep neural networks require thousands—sometimes millions—of data points to achieve high accuracy. If an organization has a limited dataset, traditional machine learning models often perform better and cost less to build.
- High Computing Costs and Infrastructure: Training deep neural networks demands substantial computational power from expensive specialized hardware like GPUs. This can result in significant cloud infrastructure costs for developing businesses.
- The “Black Box” Explainability Issue: Because a deep learning model distributes its decision-making across millions of interconnected mathematical weights, it can be incredibly difficult for an engineer to explain exactly why a model made a specific prediction. This lack of transparency can create challenges in highly regulated fields like healthcare or criminal justice.
- Algorithmic Bias: A deep learning model is only as fair and objective as the data used to train it. If the training dataset contains historical human biases or lacks diverse representation, the model will learn and amplify those errors in its real-world predictions.
Practical Strategies and Solutions
To mitigate these limitations, the AI industry has developed several practical frameworks:
- Transfer Learning: A technique where developers take a large model that has already been pre-trained on millions of data points by a major technology company, and fine-tune it using a much smaller dataset specific to their business. This slashes both data requirements and computing costs.
- Explainable AI (XAI) Frameworks: Tools like SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-agnostic Explanations) are increasingly integrated into enterprise models. These tools help unpack the “black box” by generating human-readable charts that illustrate which specific input variables had the greatest impact on the model’s final decision.
- Rigorous Bias Auditing: Data teams increasingly employ proactive data profiling and algorithmic auditing to scan training sets for imbalances before training begins, ensuring model outputs are fair, reliable, and equitable.
AI and Deep Learning Career Opportunities
The widespread adoption of artificial intelligence across the global economy has generated a strong, sustained demand for skilled professionals who can design, implement, and maintain deep learning systems.
Machine Learning Engineer
- Core Responsibilities: Serving as the bridge between data science and software engineering, ML engineers take experimental models designed by researchers and scale them up into robust, production-ready software applications.
- Key Skills: Strong proficiency in Python, deep familiarity with PyTorch or TensorFlow, solid software engineering principles, and experience building APIs.
Data Scientist
- Core Responsibilities: Data scientists analyze large volumes of unstructured corporate data to extract meaningful trends, build exploratory predictive models, and present data insights to company executives to guide business strategy.
- Key Skills: Solid understanding of statistical analysis, fluency in SQL and Python, data visualization expertise, and strong business communication skills.
Deep Learning and AI Researcher
- Core Responsibilities: Working at the cutting edge of the industry, AI researchers design entirely new neural network architectures, invent advanced optimization algorithms, and publish academic papers that push the boundaries of what machines can achieve.
- Key Skills: Advanced academic background in mathematics or computer science, deep knowledge of algorithmic theory, and extensive experience with experimental model design.
MLOps Engineer
- Core Responsibilities: MLOps engineers focus on the infrastructure side of AI. They automate the deployment, continuous monitoring, scaling, and periodic retraining of deep learning models on live production cloud servers.
- Key Skills: Deep expertise in containerization tools like Docker, orchestration platforms like Kubernetes, cloud systems (AWS, Google Cloud, or Azure), and continuous integration pipelines.
Beginner Roadmap for Learning Deep Learning
Entering the world of deep learning can feel overwhelming if you try to learn everything at once. Following a structured, step-by-step learning roadmap can help keep your educational journey efficient and highly rewarding.
+--------------------+ +--------------------+ +--------------------+
| Step 1: Foundation | --> | Step 2: Core ML | --> | Step 3: Deep Learn |
| Math & Python | | Data & Regression | | Neurons & Framework|
+--------------------+ +--------------------+ +--------------------+
|
+--------------------+ +--------------------+ |
| Step 5: Advanced | <-- | Step 4: Specialization |
| MLOps & Deployment | | Computer Vision/NLP| <------------/
+--------------------+ +--------------------+
Step 1: Build the Math and Programming Foundations
Before writing complex network code, master the fundamental tools of the trade. Spend time learning basic Python programming, focusing on core libraries like NumPy (for mathematical matrices) and Pandas (for data manipulation). Concurrently, brush up on foundational mathematics: linear algebra (vectors and matrices), basic calculus (derivatives and gradients), and fundamental probability and statistics.
Step 2: Master Traditional Machine Learning Basics
Do not skip straight to deep learning. Start by learning classical machine learning concepts using simpler libraries like Scikit-learn. Build a solid understanding of fundamental algorithms like linear regression, decision trees, and clustering techniques. Learn how to split your data into clean training and testing sets, and practice evaluating your models using metrics like accuracy, precision, and recall.
Step 3: Understand Core Neural Network Concepts
Once you understand classical machine learning, move into the fundamentals of deep learning. Study how an individual artificial neuron processes data, how weights and biases shift, and how activation functions filter signals. Pick one primary framework—either PyTorch or Keras—and practice building very simple, shallow neural networks that can classify basic tabular data.
Step 4: Dive into Specialization (Computer Vision or NLP)
With the fundamentals down, choose a specialized domain that aligns with your career goals. If you are fascinated by visual data, study Convolutional Neural Networks (CNNs) and work on projects involving image classification or object detection. If you prefer human language, explore Recurrent Neural Networks (RNNs) and modern Transformer architectures to build text generators or sentiment analysis tools.
Step 5: Learn Deployment and MLOps Concepts
To truly stand out in the job market, learn how to get your trained models out of your local coding environment and into the real world. Learn how to wrap a model in a simple web framework like FastAPI, package the entire application inside a Docker container, and deploy it to an accessible cloud platform.
Hands-on Practice Projects for Beginners
The absolute best way to solidify your theoretical knowledge is through active, hands-on experimentation. Consider building these three introductory projects:
- The MNIST Handwritten Digit Classifier: The traditional “Hello World” project of deep learning. Build a basic neural network that reads a 28×28 pixel grayscale image of a handwritten number and accurately predicts the correct digit.
- House Price Prediction Model: Use a public dataset to build a simple deep learning regression model that analyzes structural inputs—such as square footage, neighborhood crime rates, and school proximity—to forecast a property’s final market value.
- Customer Churn Predictor: Build an enterprise-focused neural network that analyzes historical customer usage metrics, contract lengths, and support ticket counts to predict which clients are most likely to cancel their subscriptions.
Certifications and Training
Earning an industry-recognized professional certification can help validate your technical skills, build confidence, and structure your learning journey effectively.
| Certification Title | Target Skill Level | Ideal For | Core Technical Skills Covered |
| Deep Learning Specialization (DeepLearning.AI) | Beginner to Intermediate | Aspiring Data Scientists and Machine Learning Engineers | Neural Network design, Hyperparameter tuning, Convolutional Networks, Sequence Models. |
| TensorFlow Developer Certificate (Google) | Intermediate | Application Developers and Software Engineers | Practical model building in TensorFlow, Computer Vision applications, Natural Language Processing. |
| AWS Certified Machine Learning – Specialty | Advanced | Cloud Architects and Enterprise DevOps Professionals | Managing cloud AI infrastructure, scalable model deployment, data pipeline engineering, MLOps. |
| Google Cloud Professional ML Engineer | Advanced | Enterprise MLOps Engineers and Infrastructure Architects | Production-grade AI architecture design, data pipeline automation, Vertex AI operations, framework scaling. |
Common Beginner Mistakes
When starting out in deep learning, it is incredibly easy to fall into a few common learning traps:
- Ignoring the Math Fundamentals: Many beginners rush straight to copying complex framework code without understanding the underlying matrix multiplication or gradient descent math. When a model fails to train correctly, they struggle to debug it because they do not understand how the parameters interact.
- Rushing into Complex Frameworks Too Fast: Trying to write complex, enterprise-grade TensorFlow pipelines on day one can lead to frustration. Start with simpler user interfaces like Keras, or follow step-by-step PyTorch tutorials to build your confidence gradually.
- Skipping Thorough Data Cleaning: Beginners often assume that the secret to a great model lies entirely in tweaking the neural network’s architecture. In reality, feeding messy, un-normalized, or duplicate data into an incredibly advanced network will still yield poor results. Spend the majority of your project time cleaning and preparing your data.
- Overfitting Your Models: It is easy to feel triumphant when your model achieves a 99% accuracy rate on your training dataset. However, if you fail to validate the model on completely separate data, you may find that it has simply memorized the answers and cannot make accurate predictions in real-world scenarios.
Best Practices for Learning Deep Learning
To maximize your learning efficiency and build a strong foundation in AI development, incorporate these core practices into your study routine:
- Prioritize Concepts Over Code Syntax: Framework syntaxes will change, update, and evolve over time, but the core mathematical principles of neural networks—like backpropagation, loss functions, and optimization—remain constant. Focus heavily on understanding why these concepts work.
- Start Small and Scale Up Gradually: When building a new project, start with a tiny, clean dataset and a basic neural network with just one or two hidden layers. Once you verify that the model compiles, runs, and learns successfully, gradually add more layers and expand your dataset.
- Document and Showcase Your Work: Do not let your practice projects sit hidden on your local computer. Upload your clean code to repositories like GitHub, write brief summaries explaining how you preprocessed the data and optimized your model, and share your insights with peer communities. This active documentation builds a strong professional portfolio for potential employers.
- Embrace Continuous, Lifelong Learning: The field of artificial intelligence moves at an incredibly rapid pace. Set aside a small block of time each week to read foundational AI research blogs, explore open-source community forums, or review educational tutorials to keep your technical skills sharp and current.
Future of Neural Networks and Deep Learning
The landscape of deep learning continues to evolve rapidly, driving fresh technological shifts that will define the next generation of software engineering and enterprise operations.
- Generative AI and Foundation Models: Large-scale neural networks have advanced from merely classifying existing data to creating completely new content. Advanced foundation models process multimodal streams—handling text, complex code, imagery, and audio simultaneously—to act as collaborative intelligent partners across various industries.
- Edge AI and Localized Computing: Traditional deep learning models require heavy, centralized cloud data centers to process information. The industry is seeing a major shift toward Edge AI, where optimized, lightweight neural networks run locally directly on consumer hardware like smartphones, wearable medical sensors, and automotive microchips, allowing for instantaneous processing with zero latency.
- Explainable AI (XAI) and Automation: As artificial intelligence takes on high-stakes responsibilities in sectors like medicine, aviation, and corporate finance, the demand for transparent systems is higher than ever. Future deep learning architectures will increasingly incorporate automated explainability features, allowing systems to provide clear, human-understandable records of their decision-making logic.
FAQs (Frequently Asked Questions)
1. What is deep learning in simple words?
Deep learning is a specific branch of machine learning where computers learn to find complex patterns in data by using multi-layered artificial neural networks. Instead of a human programmer writing strict rules for the computer to follow, the system learns how to make decisions on its own by analyzing thousands of real-world examples.
2. How are neural networks inspired by the human brain?
Neural networks are conceptually modeled after the brain’s biological structure. In a biological brain, organic neurons pass chemical and electrical signals to process thought. In an artificial neural network, software-based nodes are organized in layers to pass mathematical values, adjusting their internal weights to learn from mistakes over time.
3. Is advanced mathematics absolutely required for deep learning?
You do not need an advanced degree in mathematics to begin building deep learning models, as modern software libraries handle most of the complex calculations under the hood. However, having a basic grasp of linear algebra, calculus derivatives, and core statistics is highly valuable for understanding how models learn and debugging them when things go wrong.
4. Which programming language is best for learning AI?
Python is the undisputed leading language for artificial intelligence and deep learning. It features a clean, highly readable, and human-friendly syntax, combined with an enormous open-source ecosystem of libraries like PyTorch, TensorFlow, Keras, and Pandas.
5. Can absolute beginners learn deep learning?
Yes, absolutely. Anyone can learn deep learning provided they follow a structured, step-by-step learning roadmap. The key is to start with programming and basic machine learning fundamentals before diving directly into highly complex multi-layered neural network architectures.
6. What major industries use deep learning today?
Deep learning is actively used across a wide variety of industries. Key examples include healthcare (for automated medical imaging diagnostics), finance (for real-time fraud detection and portfolio analysis), retail (for personalized recommendation systems), and transportation (for autonomous self-driving vehicle systems).
7. How long does it typically take to learn deep learning basics?
For a student or professional who already understands basic Python programming, mastering the fundamental concepts of deep learning usually takes around 3 to 6 months of consistent study. Reaching an advanced, production-ready enterprise engineering level typically requires a year or more of practical, hands-on project experience.
8. Is an expensive GPU hardware setup required to study deep learning?
No, you do not need to buy expensive computer hardware to start learning. Free cloud-based coding environments, such as Google Colab, provide students with complimentary access to high-powered GPU resources directly through a standard web browser, making deep learning accessible to anyone with an internet connection.
9. What is the difference between supervised and unsupervised learning?
Supervised learning involves training a neural network using a dataset where every single input example is paired with a clear, correct answer label (ground truth). In unsupervised learning, the network receives raw data without any labels and must discover underlying patterns, structures, or groupings completely on its own.
10. What is overfitting and how can you prevent it?
Overfitting occurs when a neural network learns the training data too perfectly, memorizing the specific examples along with their noise and random fluctuations. As a result, it performs flawlessly on training data but fails to make accurate predictions on new data. You can prevent overfitting by using techniques like dropout layers, early stopping, and validating your model on a separate dataset.
11. What is a Convolutional Neural Network (CNN)?
A Convolutional Neural Network is a specialized neural network architecture designed specifically for processing spatial data, such as images and video streams. CNNs use mathematical layers called convolutions to automatically detect local features—like edges, textures, and shapes—regardless of where they appear in a picture.
12. What is the role of a loss function in training?
A loss function is a mathematical formula that measures the exact error margin between a neural network’s automated prediction and the actual correct label. It provides a concrete numerical score that tells the network how well or poorly it is performing, guiding the optimization algorithm on how to adjust internal weights.
13. What does the term “deep” mean in deep learning?
The word “deep” refers specifically to the structural number of hidden layers built into a neural network. While early, traditional neural networks only featured one or two processing layers, modern deep learning models often utilize dozens, or even hundreds, of interconnected processing layers to extract highly complex patterns from data.
14. How do weights and biases alter a network’s decisions?
Weights act as mathematical multipliers that determine how much influence a specific input value has on a neuron’s final output. Biases function as an additive offset, shifting a neuron’s activation threshold up or down independently of the incoming data values to help fine-tune predictions.
15. Where can I find good open-source datasets to practice with?
Public platforms like Kaggle, the UCI Machine Learning Repository, and Google Dataset Search offer thousands of completely free, high-quality datasets covering fields like healthcare, finance, image recognition, and sports, giving beginners ample material for practical practice projects.
Final Thoughts
Embarking on your journey into neural networks and deep learning means opening the door to one of the most transformative technological landscapes of our era. As an AI mentor, my most critical piece of advice is to resist the temptation to treat this field as a collection of black-box software tools. The code syntax for defining a layer in PyTorch or Keras can be learned quickly, but true professional expertise lies in developing a deep conceptual understanding of why these systems learn, how data behaves as it flows through layers, and how optimization math drives improvement.
Focus heavily on the fundamentals, take the time to clean your datasets thoroughly, and embrace the iterative process of trial and error. The global demand for individuals who can build stable, ethical, and scalable deep learning models is immense and growing. By anchoring your education in hands-on experimentation and solid core principles, you position yourself to be an active driver of the ongoing intelligent systems transformation. Turn on your development environment, start with a simple project, and take it one step at a time.