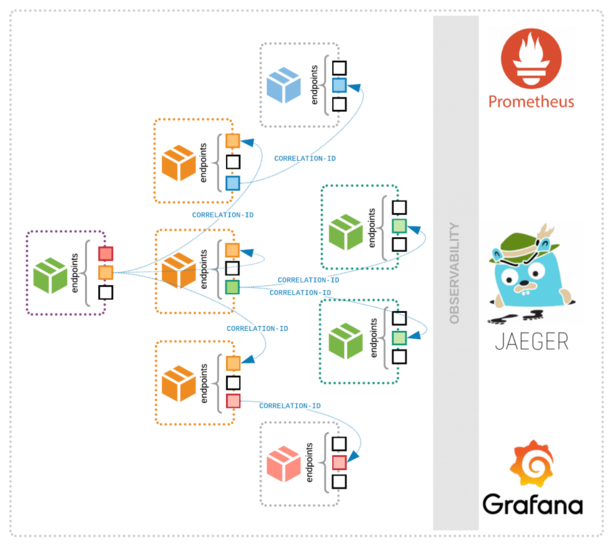
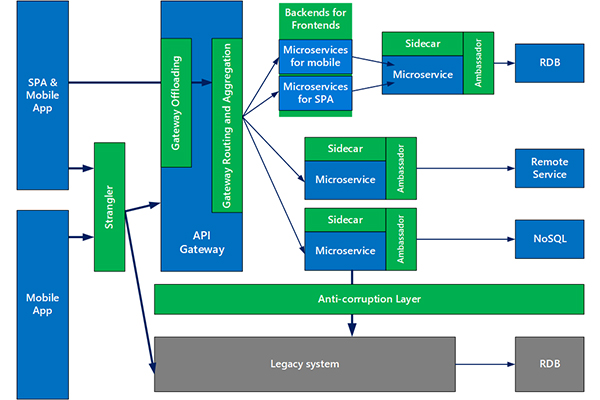
Source: searchapparchitecture.techtarget.com
In order to operate correctly, microservices need to discover each other in an intelligent manner. Some development teams try to manage this by locating where particular microservices are at a single point in time, and then writing code that links these locations together. The problem is the location of these microservices can change abruptly. If the code is tied directly to those locations, the services will fail as the architecture changes.
Organizations need a mechanism to change how microservices transmit their state and location. This is where service discovery comes to the rescue, which uses a dynamic database registry of available microservices to determine where each instance resides at any given time. This registry operates through both a management and a query API set, where the management API registers the microservices and the query API calls them.
In this tip, we’ll examine the basics of service discovery in a microservices architecture, including:
- the differences between client-side vs. server-side discovery;
- the specifics of self-registration vs. third-party registration; and
- the three most common service registry scenarios.
Client-side vs. server-side discovery
With client-side service discovery, it’s the client’s responsibility to identify where the needed microservices are at any time. The client operates its own service registry by maintaining and regularly updating a dynamic list of available microservices. Although this approach has its pros, such as being helpful with load balancing, the major drawback is that every client must constantly retain the logic it uses to interact with the microservices.
Server-side service discovery keeps the registry on the other side of the fence, generally behind a load balancer. Again, this service registry contains a dynamic list of all available microservices and their current location. The benefit here is that it only requires a single service registry. However, architects must ensure that this registry maintains high availability, perhaps via live mirroring of the registry across the cluster of instances. Also, they need to carefully manage service caches to mitigate data inconsistencies.
Self-registration vs. third-party registration
Microservices must be able to both add and remove themselves from a service registry. This can be accomplished via either a self-registration or third-party registration approach.
In the self-registration approach, the microservice retains the code specific to the service registry in use. For example, Netflix OSS has its own service registry, Eureka. Any microservice that wants to register with it just needs to have the @enableEurekaClient annotation within its code. A more generic approach to this would use lines such as:
Register("microservicename, "<ipaddress:port>")
Heartbeat()
Unregister()
With self-registration, it’s the microservice’s job to tell the registry when it is and isn’t available. This requires that the microservice be able to send a message to the registry even in the event of a total failure. As with client-side discovery, self-registration needs to be applied for every framework being used.
In third-party registration, a service registrar takes over the job of constantly registering and monitoring the microservices in the service registry. The registrar investigates the general collection of services, and creates the code required to add the microservice to the registry once it finds the right one. It will also maintain a list of non-available microservices, eliminating the need for the individual microservices to announce a failure.
Of course, this registrar must be able to recognize new microservice entities and readily support the specific service registry you use. Preferably, the registrar should support a large number of registry types from the get-go.
The three main types of service registry scenarios
There are three main types of service registry scenarios you are likely to come across:
- A “home-grown” environment where development teams coded their own service registry to deal with client-side or server-side microservice interactions. This is not recommended as maintaining such a platform is difficult and prone to error.
- A distributed data store service that provides a service registry, but requires self-registration. Platforms such as Apache Zookeeper fall into this camp.
- An orchestration framework that provides both a service registry and registrar, and automatically handles third-party registration. Examples of these orchestration frameworks include Netflix OSS, Kubernetes and Marathon.
The choice comes down to the development team’s preferences — it is not recommended to try and mix these approaches. Self-registration offers a slightly higher degree of control and granularity in regard to the registration process. On the other hand, third-party registration provides simplicity and automation.
However, it may be your existing platforms that force the decision. If your team is already using Kubernetes, then automatic registration is the easy option. If using etcd, then you can choose to either use self-registration or introduce a separate third-party registrar. Registrator, an open source system that supports etcd, is an example of one of these third-party registrars.
Overall, third-party registration with server-side service discovery in microservices is the preferred approach, as it provides a way around the problems of complex client-side architectures. However, the precise details of your own existing platform will likely dictate your choice.